

[WITH CODE] Switch-off: Robust changepoint protocol
A robust changepoint-based switch-off protocol for algorithmic trading

Table of contents:
Introduction.
The drift in algorithm performance.
Taxonomy of performance drift.
Model risks and limitations.
Robust estimation and the biweight loss.
M-estimators and the geometry of influence.
Tukey’s Biweight (bisquare) loss.
Iteratively Reweighted Least Squares (IRLS).
Regime segmentation via penalized dynamic programming.
The PELT Algorithm (Pruned Exact Linear Time).
The pruning inequality.
Phase 1: Cost Matrix precomputation.
Phase 2: The PELT solver.
Reconstruction and visualizing the drift.
Logic A: Relative decay (alpha erosion).
Logic B: Absolute failure (negative expectancy).
Before you begin, remember that you have an index with the newsletter content organized by clicking on “Read the newsletter index” in this image.

Introduction
Every live strategy is a slowly degrading asset. Not because the model was bad, but because the market keeps changing.
When we deploy an algorithm, we behave as if the distribution that generated its backtest will hang around just long enough for us to harvest the edge. We roll windows, we recalibrate, we monitor drawdowns and Sharpe ratios—all under an implicit truce: whatever drives our PnL won’t change too fast. In practice, that truce is routinely violated.
Edges are conditional stories about the world. Microstructure, liquidity, crowding, policy, fees, latency, and even hardware shape the conditional law that turns a set of signals into returns. Those conditions drift. Sometimes slowly, as competitors discover the same inefficiency and squeeze the juice out of it. Sometimes brutally, as a change in market structure or regulation flips the sign of the trade overnight. From the PnL point of view, both scenarios look like one thing: a strategy that once worked… now doesn’t.
The core operational problem is simple to state and hard to solve:
When does a drawdown stop being noise and become a structural break?
Look at it from the supervisor’s perspective. You observe a noisy sequence of PnL: good days, bad days, occasional 5–10σ events courtesy of fat tails and slippage. Somewhere inside that, the expected value of the strategy can jump from strongly positive to mildly positive, from mildly positive to mediocrity, or from mediocrity to outright negative. Your job is to distinguish those regime changes from random turbulence—fast enough to avoid ruin, slow enough to avoid killing healthy engines.
Standard risk tools are not built for this. Sharpe ratio, volatility targeting, VaR and its cousins are all about dispersion. They tell you how wild the ride is, not whether the underlying game has changed. In fat-tailed, heteroscedastic PnL, a violent loss is weak evidence of anything. A single execution error or fat-finger trade can destroy your mean while telling you nothing about the underlying alpha. Naive responses—Z-score kill switches, rolling-window Sharpe cutoffs, 3σ and you’re out—confuse outliers with structural decay.
At the same time, humans are terrible at making this call in real time. Six months of research sunk into a model, a couple of decent years in production, a rough patch that might be noise or might be decay. The quant knows the theory, the PM sees the drawdown, the committee wants just a bit more evidence. So the strategy stays on. One more week. One more month. One more quarter. By the time everyone agrees it’s dead, the damage is already done.
This article is about replacing that improvisation with a protocol. The implementation was inspired by this paper

Although several modifications were made for our purpose (switch-off tool). Therefore, it is not exactly the same nor does it serve to detect the same thing.
The drift in algorithm performance
A pervasive working assumption in quantitative trading is not full stationarity, but some degree of structural persistence. When we calibrate a model, we estimate parameters θ on a historical sample under the practical assumption that the conditional law driving decisions will not change too fast:
at least in the parts of the state space that matter for our strategy. Even when we use rolling windows, online learning, or adaptive rebalancing, we are implicitly assuming that concept drift is slower than our learning and turnover cycle—that we can track the moving target before we hit a ruin boundary.
In the markets this is, at best, an approximation and often a dangerous one. The return-generating mechanism is subject to regime shifts, structural breaks, policy interventions, technological change, and competition for the same signals. Alpha is not literally defined as a disequilibrium, but operationally it behaves like one:
It is a predictable deviation from what competing capital currently prices in. In a frictionless, unconstrained market, any such predictable excess return is self-destructive: as capital scales into the trade, the pattern is arbitraged away, its Sharpe collapses, and its behaviour migrates towards noise.
This means that alpha decay is not a bug in the research process but the default equilibrium outcome. A deployed strategy is engaged in a race between three clocks:
The decay time of the inefficiency as others discover and crowd it.
The adaptation time of our models and infrastructure.
The risk horizon over which drawdowns become existential.
Stationarity, in this light, is not a realistic global assumption but a local, temporary truce between these clocks. Robust design does not assume that P(X, y) is stationary; it assumes that edges have a finite half-life, and builds everything—the research loop, deployment, and switch-off logic—around surviving long after the original pattern has started to die.
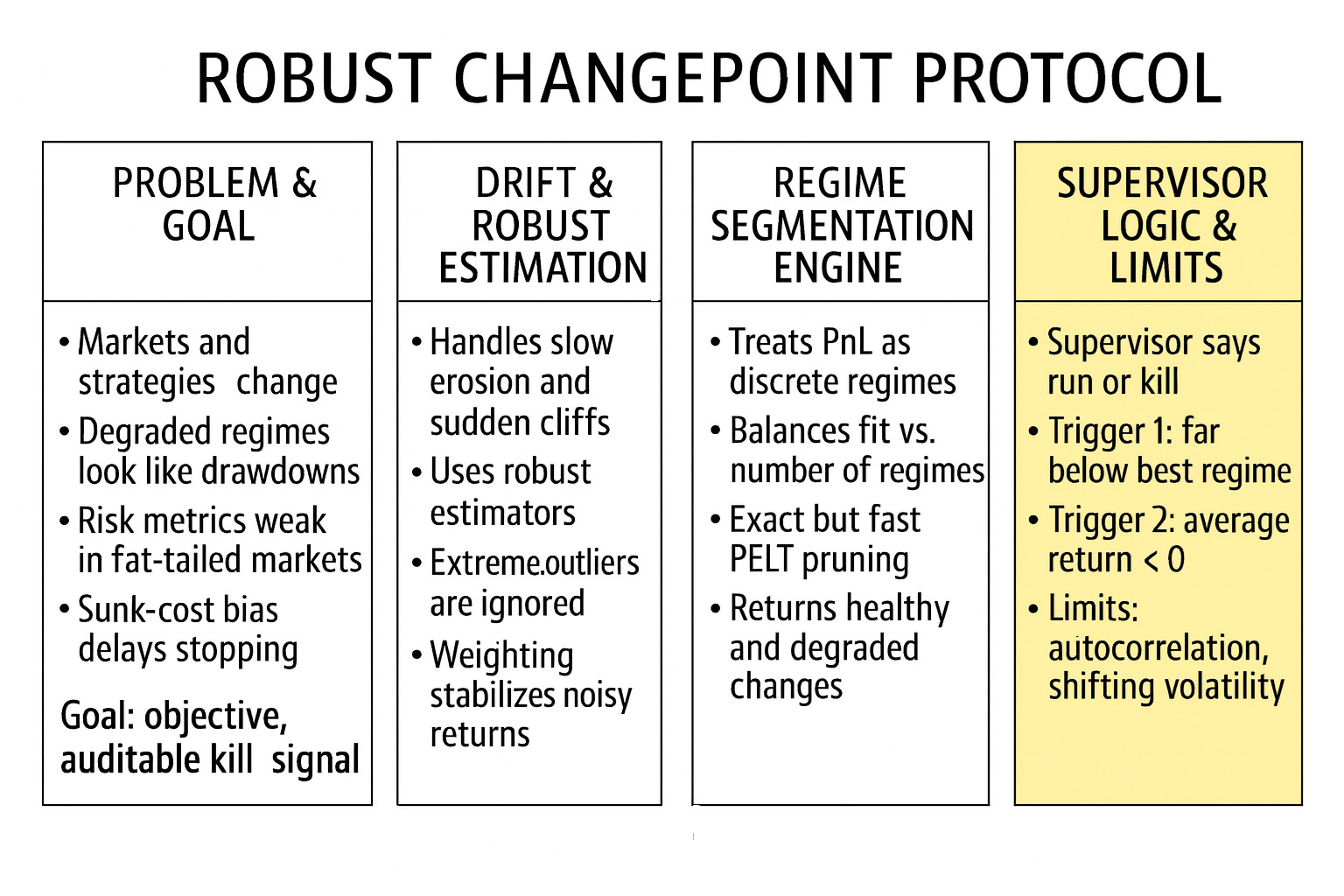
Empirical observation across multiple asset classes—from market making to low-frequency statistical arbitrage—suggests that strategies do not fade linearly. Instead, they exhibit distinct, abrupt regimes. A strategy typically oscillates between:
Healthy regime: Positive expectancy (E[r] > 0), stable variance (σ2 ≈ constant), and high information ratio.
Degraded regime: Zero or negative expectancy, often accompanied by volatility clustering where variance spikes due to liquidity constraints, crowding, or breakdown in the correlation structure.
The trader’s dilemma arises when the realized PnL sequence R = {r1, r2, …, rt} deviates from the expected value E[R]. The operator is essentially solving a high-stakes signal classification problem in real-time, often under immense psychological pressure and incomplete information:
Hypothesis H0 (null hypothesis - noise): The deviation is merely sampling variance. The strategy’s edge is intact (E[r] > 0). The drawdown is a statistical artifact of the variance, not a bias in the mean. Action: Do nothing.
Hypothesis H1 (alternative hypothesis - broken): The deviation is structural. The strategy’s edge has evaporated (E[r] ≤ 0). The drawdown is a function of a new, adverse mean. Action: Halt trading.
Because financial time series exhibit high kurtosis (fat tails) and heteroscedasticity (changing variance), a large negative return rt provides surprisingly weak evidence for H1 in isolation. A standard 3σ event—which happens once every 740 years in a Gaussian world—might occur every month in a live trading strategy. Consequently, standard variance-based risk metrics (like Value at Risk, Sharpe Ratio, or volatility targeting) usually fail in this specific context because they measure the magnitude of the dispersion, not the shift in the underlying data generating process.

Taxonomy of performance drift
To correctly diagnose the failure of a strategy, we must move beyond generic labels like drawdown or bad luck and categorize the statistical nature of the failure. We define two primary categories of drift that necessitate a switch-off protocol.
In the previous article, we discussed the different types of drift from a time series perspective, in our case, PnL. Take a look:
![[WITH CODE] Switch-Off: Bayesian online changepoint detection](https://substackcdn.com/image/fetch/$s_!AJt2!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5cedd76e-1949-481c-a904-be1a249336c5_1280x1280.png)
Covariate drift → environmental shift.
Covariate drift occurs when the distribution of the inputs P(X) changes while the conditional probability of the target P(y|X) remains constant.
The market environment shifts, starving the model of its necessary preconditions. Consider a Mean Reversion strategy trained on high-volatility regimes (Xtrain ∼ N(0, σhigh). If the market enters a prolonged period of low volatility (central bank pinning, summer doldrums), the distribution of spread opportunities P(X) collapses.
The strategy’s logic remains mathematically sound—if a spread did open, it would likely close—but the opportunities simply do not arise. The PnL flatlines. However, because the strategy effectively pays rent (server costs, data fees, minimum commissions, and slippage on desperate fills), the net PnL begins to bleed slowly.
This is often termed regime mismatch. While the alpha is not strictly broken, the capital is inefficiently deployed. The correct response may be to hibernate the strategy rather than kill it, but from a PnL perspective, it must be switched off to preserve Sharpe.
Concept drift → alpha decay
Concept drift occurs when the relationship between the signal and the target changes, i.e., P(y|X) shifts. This is the most dangerous form of drift.
The market structure evolves, or the signal becomes crowded.
Example 1 (crowding): A proprietary signal based on order book imbalance worked when you were the only user. Now, five hedge funds are using the same signal. The predictive power X is still visible, but by the time you execute, the price impact of competitors has erased the profit margin. P(y>0|X) drops to near zero.
Example 2 (microstructure): A strategy relies on a latency arbitrage between two exchanges. The exchange updates its matching engine, reducing the latency delta. The physical reality of the arb disappears.
The strategy continues to take trades that look historically valid, but the expected return of those trades shifts from positive to negative. The PnL exhibits a persistent negative trend (drift) that is statistically distinguishable from zero.
This is a structural break. The alpha is dead. No amount of parameter retuning will fix a broken thesis. This requires immediate, permanent cessation of trading.
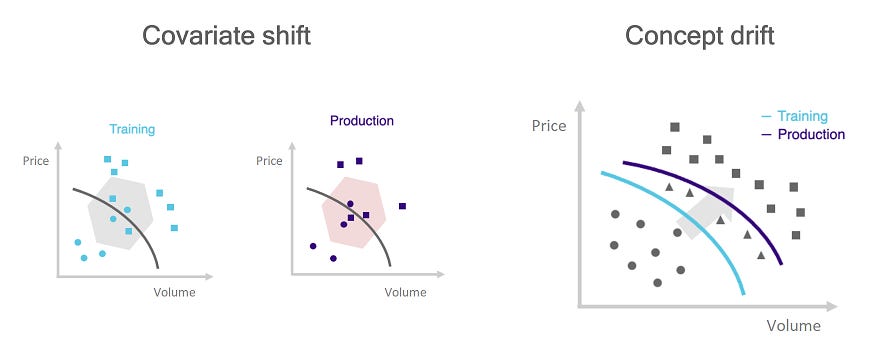
The speed of the drift determines the difficulty of detection.
Gradual drift (the boiled frog): Typical of alpha decay due to competition. The Sharpe ratio erodes from 2.0 to 1.5 to 1.0 over a period of months. This is the hardest to detect because each incremental drop is masked by the daily noise. The operator rationalizes it as a slightly tough month, failing to integrate the long-term trend.
Sudden drift (the cliff edge): Typical of structural breaks, such as a regulatory ban on a specific order type, a change in the maker-taker fee model, or a shift in the tick size. The mean PnL jumps instantaneously from μpositive to μnegative. While the magnitude is larger, the suddenness makes it easier to detect with changepoint algorithms, provided they are robust to outliers.
Our Robust Changepoint Detection model (RCD) is specifically designed to distinguish these structural drifts from mere volatility expansion.
In the absence of a rigorous framework, the decision to stop is psychological rather than statistical. This leads to the sunk cost behavior pattern, well-documented in behavioral finance but particularly acute in quantitative R&D. A quant team may spend 6 months developing a model. When it degrades, the emotional cost of admitting the 6 months of work is now obsolete is incredibly high.

The quant observes a degradation in performance but delays the switch-off decision, waiting for one more data point to confirm the trend. This one more data point is a statistical fallacy; in a noisy time series (Signal-to-Noise << 1), a single point contributes almost zero information gain regarding the regime hypothesis.
This delay is the pivotal source of excess loss in quantitative funds. The conflict is between the human desire for continuity (and the ego associated with the model’s creation) and the statistical reality of the data. We resolve this conflict by removing the human operator from the decision loop entirely. The pivotal event is the automated execution of the switch-off signal, driven purely by the posterior probability of a regime change. The supervisor code becomes the final arbiter of the strategy’s life, acting as a meta-strategy that trades the portfolio of sub-strategies.
Model risks and limitations
While the RCD protocol significantly reduces the risk of ruin compared to naive stop-loss heuristics, it is not a panacea. It introduces a secondary layer of model risk. We are effectively trading one set of assumptions (market stationarity) for another (regime stationarity and independence). Understanding the boundaries of this model is as critical as understanding the strategy it supervises.
The standard formulation of the PELT algorithm, as implemented in this protocol, assumes that the residuals within a regime are Independent and Identically Distributed (i.i.d): ϵt ∼ N(0, σ).
Algorithmic trading PnL is rarely i.i.d.
Mean Reversion Strategies often exhibit negative autocorrelation.
Trend Following Strategies often exhibit positive autocorrelation (streaks/momentum).
Positive autocorrelation reduces the effective sample size. If a strategy has a lucky streak (autocorrelated wins), the PELT algorithm may interpret this cluster of wins as a distinct high alpha regime. When the streak inevitably reverts to the mean, the algorithm detects a regime shift downwards. This leads to over-segmentation. We detect shifts that are merely artifacts of the serial dependence, leading to potential Type I errors (premature switch-off).
For highly autocorrelated strategies, the PnL series should ideally be pre-whitened or the penalty parameter must be inflated to account for the reduced degrees of freedom.


Besides, the system’s decision boundary is heavily dependent on two hyperparameters: the penalty and the robustness scale K. We typically calibrate K based on a long-term estimate of volatility. However, volatility itself is regime-dependent.
If the market transitions from a low-vol to a high-vol regime without a change in expectancy (Signal-to-Noise drops, but Mean is stable), a static K may interpret the new normal variance as a series of outliers. The biweight loss function will “clip” these valid data points, causing the estimator to become unresponsive or erratic.
The current implementation assumes a relatively homoscedastic noise structure within regimes or relies on the Biweight to simply ignore heteroscedasticity. It does not explicitly model changing volatility regimes as distinct from mean regimes.
The protocol provided is explicitly a switch-off logic. It acts as a circuit breaker. It does not provides a signal for re-entry.
If the supervisor switches off a strategy due to a detected negative drift (Type II Drift), and the strategy subsequently recovers in a simulation-trading environment, the algorithm offers no criteria for reactivation.
There is a significant risk of missing the recovery. Strategies often decay due to temporary crowding and recover when competitors exit (the “ecological cycle” of alpha). By automating the exit but leaving the re-entry to human discretion, we introduce a new behavioral bias: the fear of re-engaging with a failed strategy. This asymmetry can lead to under-allocation during the strategy’s renaissance.
Robust estimation and the biweight loss
In the domain of financial time series, the Ordinary Least Squares estimator is dangerously fragile. While it is the Maximum Likelihood Estimator for Gaussian distributions, its performance degrades catastrophically in the presence of heavy-tailed noise.
To quantify this fragility, we utilize the statistical concept of the breakdown point. The breakdown point of an estimator is the smallest fraction of observations that need to be replaced by arbitrary values to cause the estimator to take on an arbitrarily large value (i.e., to become useless).
The breakdown point of the arithmetic mean is 1/n (asymptotically 0). This implies that a single data point, if sufficiently large, can pull the sample mean to infinity.
The breakdown point of the median is 0.5 (50%). Half the data must be corrupted before the median becomes unreliable.
Consider a strategy with a Sharpe ratio of 2.0. In a typical window of 100 trades, it generates returns clustered tightly around a mean of +0.05R. Our scenario would be something like: A single execution error results in a -50R loss.
Result (mean): The sample mean for the window instantly drops to negative territory. A variance-based switch-off logic (like a Z-score) immediately triggers.
Result (robust): A robust estimator identifies the -50R event as distinct from the data generating process of the alpha. It isolates the outlier, discards it, and correctly identifies that the remaining 99 trades still exhibit a +0.05R expectancy.
The switch-off logic must fundamentally distinguish between execution failure (an outlier) and alpha decay (a shift in the central tendency). The sample mean conflates these two errors.
M-estimators and the geometry of influence
We employ M-estimators, a broad class of estimators obtained as the minima of sums of functions of the data. We minimize an objective function of the form:
where ρ is a symmetric, positive-definite loss function. The choice of ρ dictates the geometry of the risk surface and how the model reacts to deviations.
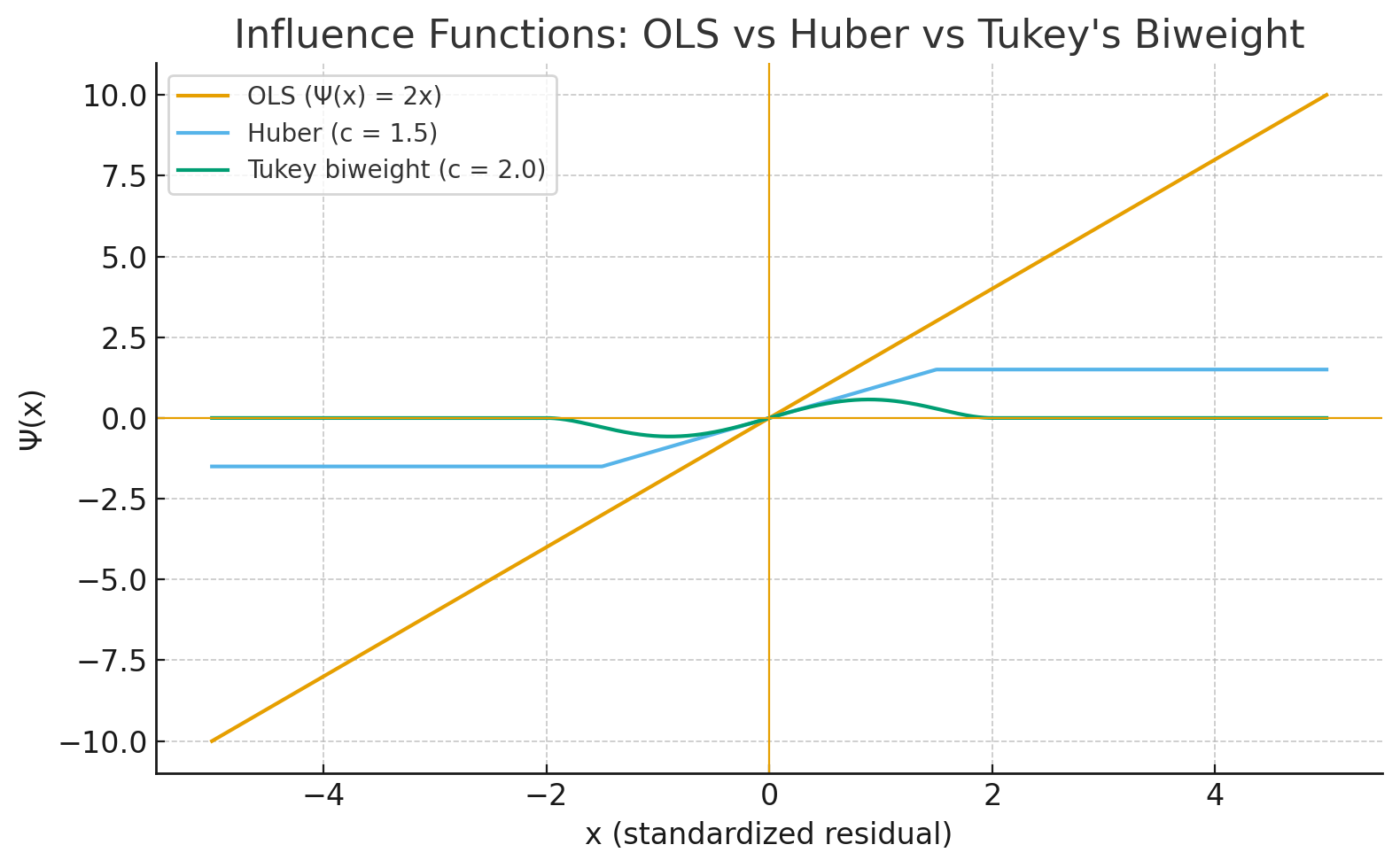
The sensitivity of the estimator to an outlier at value x is described by its influence function, which is proportional to the derivative of the loss function, Ψ(x) = ρ’(x).
Ordinary Least Squares: ρ(x) = x2.
Ψ(x) = 2x.
The influence of an error grows linearly with its magnitude. A 10σ event has 10 times the pull of a 1σ event. This is unacceptable for fat-tailed markets.
Huber Loss: ρ(x) is quadratic for small x and linear for large x.
Ψ(x) = c · sgn(x) for |x|>c.
The influence of an outlier is capped (constant). While better than OLS, it still allows extreme outliers to exert some influence on the location estimate. In a regime switch-off context, even a constant pull from a massive outlier can bias the decision.
Tukey’s Biweight:
Ψ(x) → 0 as |x| → ∞.
This is a redescending M-estimator. Once a data point is identified as being “too far” (beyond a threshold K), its influence completely vanishes. The estimator effectively performs a soft trim, ignoring the data point entirely. This is the property required for a reliable switch-off mechanism.
Tukey’s Biweight (bisquare) loss
To achieve maximum resistance to toxic flow and outliers, we utilize Tukey’s Biweight loss function.
The Biweight loss function is defined as:
The corresponding influence function Ψ(x) is:
Crucially, Ψ(x) = 0 for |x| > K.
The parameter K is not arbitrary; it represents the scale of robustness. It defines the boundary between noise (which affects the mean) and structural breaks/outliers (which should be ignored).
Typically, K is calibrated to c x Scale, where Scale is often the Median Absolute Deviation.
A common default is c=4.685 for asymptotic efficiency at the Normal distribution, but in trading, we often tighten this to c ≈ 2.5 to be more aggressive in rejecting outliers.
Iteratively Reweighted Least Squares (IRLS)
The Biweight loss function is non-convex. This means there is no closed-form solution (like the normal equations for OLS). We must solve for the location parameter θ iteratively.
We utilize the IRLS method. The logic proceeds as follows:

For computational simplicity and speed in our Python implementation (specifically to avoid complex iterative solvers in the inner loop of the dynamic programming step), we approximate the Biweight behavior using a truncated quadratic loss. This effectively clips the influence of any data point beyond distance K from the center.
This function preserves the core property we need: it is quadratic near zero (efficient for Gaussian noise in normal regimes) but constant for large |r| (robust to outliers).
We implement a simplified IRLS solver. Note the specific handling of the mask which serves as a binary weight (0 or 1) rather than the smooth polynomial weight of the full Biweight. This hard rejection is computationally faster and often preferred in high-noise signal processing.
def robust_mean_biweight(y, K, max_iter=50, tol=1e-6):
“”“
Approximate minimiser of sum_i min((y_i - theta)^2, K^2)
using a simple iterative truncated mean.
Parameters
----------
y : array_like
PnL values in one segment.
K : float
Biweight threshold. Residuals with |y_i - theta| >= K are saturated.
max_iter : int
Maximum iterations.
tol : float
Convergence tolerance.
Returns
-------
theta_hat : float
Robust mean estimate for the segment.
“”“
y = np.asarray(y, dtype=float)
if y.size == 0:
return np.nan
# Start from median for robustness
theta = np.median(y)
for _ in range(max_iter):
r = y - theta
mask = np.abs(r) < K # inliers
if not np.any(mask):
# everything is considered an outlier at this theta
return theta
theta_new = y[mask].mean()
if abs(theta_new - theta) < tol:
return theta_new
theta = theta_new
return theta
def biweight_segment_cost(y, K):
“”“
Biweight segment cost and corresponding robust mean.
Cost: sum_i min((y_i - theta)^2, K^2), theta via robust_mean_biweight.
“”“
y = np.asarray(y, dtype=float)
theta = robust_mean_biweight(y, K)
r = y - theta
loss = np.where(np.abs(r) < K, r**2, K**2)
return float(loss.sum()), thetaIt is critical to note that the Biweight loss function is non-convex. Unlike OLS (a simple bowl shape), the Biweight loss surface has multiple local minima.
If we initialize the IRLS algorithm with an arbitrary value (e.g., zero, or the previous window’s mean), the solver might get stuck in a local minimum that corresponds to a cluster of outliers rather than the main data distribution.
This is why the code explicitly initializes theta = np.median(y). The median is guaranteed to be close enough to the global minimum to place the solver within the basin of attraction of the true robust mean.