Table of contents:
Introduction.
The API layer.
Protocol semantics, transport choice, and system state.
Risk and financial APIs limitations.
Historical-live non-equivalence and data reconstruction error.
Execution state machines and order routing.
Simulation and live trading.
Creating the architecture for a trading API.
Before you begin, remember that you have an index with the newsletter content organized by clicking on “Read the newsletter index” in this image.

Introduction
Before moving on to the next series, there’s an important point that any algorithmic trader needs to know: the point about APIs.
A quant can state the issue in simple terms. Let st denote latent market state and let xt denote observed state at decision time. The strategy trades on xt rather than st. The transformation from st to xt includes vendor capture, transport, buffering, schema validation, clock alignment, and local state reconstruction. When that transformation changes, the strategy changes with it, even if the signal formula stays fixed.
The API layer belongs to the hypothesis itself because it determines the admissible information set on which the strategy acts.
This point matters because the gap between research and deployment tends to emerge at the boundary where information becomes software state. Bars in a notebook arrive sorted and complete. Live messages arrive through sessions, quotes, reconnect paths, and transport rules. Orders in a backtest pass from signal to fill in one step. Orders in production pass through acceptance, routing, queue interaction, etc. In a systematic process, those choices carry mathematical weight because they alter the state space on which the strategy operates.
The live strategy therefore admits a fuller description than the research signal alone. A useful expression is
Many teams place their energy on features, models, and optimization while the interface layer receives less formal treatment. That habit carries a cost. A signal derived from one information regime and deployed through another regime becomes a different object. A simulator that treats execution as an atomic event studies a market process distinct from the one live code encounters.
The API layer is where these fractures surface. It is also where discipline can restore coherence. If you want a stack to start with, here it is:

An API is an information contract, a timing contract, and an execution contract. That’s to say, data fields need causal meaning, timestamps need clear authority, order states need legal transitions, internal services need shared schemas across research, simulation, and live trading. Do you get the ida right? Under those conditions, performance claims acquire stronger footing because the path from observation to action remains explicit.
The subject here is the form through which market enters the strategy and the form through which strategy intent reaches the market. Code style, framework choice, and endpoint count matter through their effect on that form. A live trading stack earns coherence when the objects that move across it stay explicit, typed, and stable across the full path from research to execution. That coherence is a design choice and it begins at the API layer.
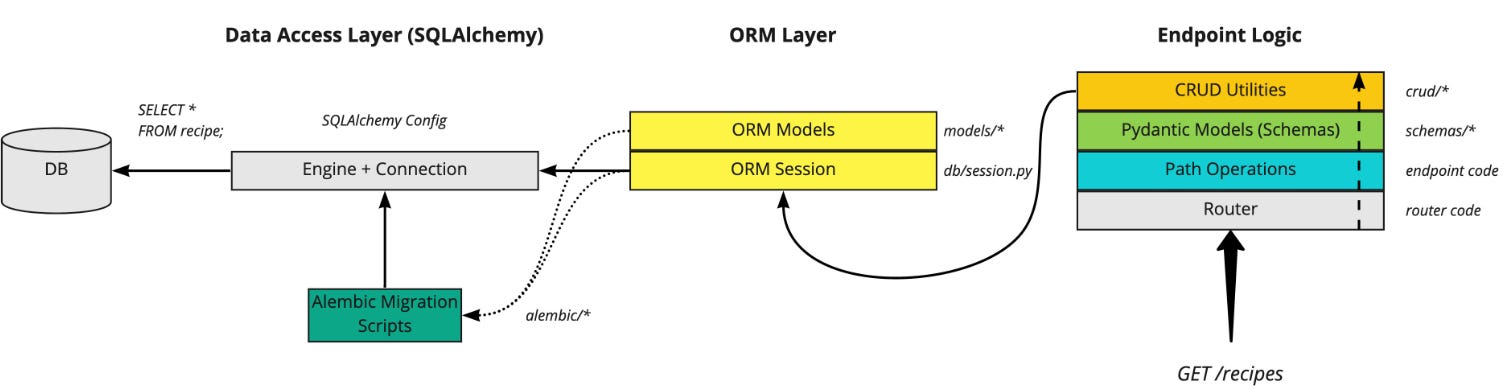
The API layer
In a trading system, the central question asks what is known, when it becomes known, and which representation carries it. The API layer lives at that boundary. It defines the admissible information set available to the strategy at decision time. That framing captures the practical source of failure with precision.
Let the latent market state at event index t be st. The strategy never accesses that state in raw form. It receives an encoded view xt, produced through venue generation, vendor capture, normalization, transport, buffering, decoding, and local deserialization. If those operations are compressed into a single operator H, then the strategy acts on
In live systems, H belongs to a family of transformations shaped by endpoint choice, session state, codec, throttling behavior, aggregation policy, and recovery logic. The research question therefore asks two things at once: whether a mapping f(xt) carries predictive value, and whether the xt used in research belongs to the same family as the xt available in deployment.
A useful decomposition is
The term Ht(s0:t) shows that observed state may depend on a path rather than a single contemporaneous latent state. Corrections, delayed packets, local aggregation, and dropped messages create that path dependence. The residual term εt collects the user-facing uncertainty generated by packet loss, schema surprises, decoder failure, clock mismatch, and hidden vendor behavior. In a calm hourly-bar strategy, εt may occupy a small role. In a short-horizon or execution-sensitive strategy, it often defines the core challenge.

This perspective dissolves a common misconception. Many quants treat the API as a latency channel and connect latency risk with high-frequency trading. A richer view sees the API as a state-visibility mechanism. Consider a breakout rule triggered when price crosses a level and volume in the same interval exceeds a threshold. One endpoint may publish aggregated bars with finalized volume, while another may publish incremental trades that require local accumulation. The rule then sees different objects.
Speed alone does not resolve that difference. One representation is final. The other is provisional. One is bounded by bar closure. The other evolves through the interval. If research evaluates the final object while deployment trades the provisional one, then backtest and live trading inhabit different information worlds.
The official protocol and framework documentation supports this view from the software side. HTTP semantics are defined as stateless at the application-protocol level. That property makes HTTP well suited for resource retrieval, explicit commands, and idempotent inspection, while state continuity moves into higher layers. The OpenAPI specification makes HTTP service capabilities machine-readable through paths, parameters, schemas, and responses. FastAPI builds on that structure by generating OpenAPI descriptions and interactive documentation from Python declarations. Pydantic treats typed data models as executable contracts and emits JSON Schema from those models. Finance gives special weight to this alignment because state integrity sits at the center of the problem.
For a systematic trading system, the internal data model becomes a compact statement of admissible knowledge. A well-defined Bar object can enforce monotonic timestamps, nonnegative volume, high-low consistency, a declared timezone, and provenance metadata. A Signal object can enforce a causal timestamp, a horizon, a generation identifier, and a confidence field interpreted consistently by the risk layer. An OrderIntent object can separate intent from broker acknowledgment, so the system preserves a clean distinction between desired action, accepted action, and executed action. These structures carry operational value because they keep portfolio state, execution state, and research state aligned across time.

Protocol semantics, transport choice, and system state
A familiar hierarchy pairs REST with slower interactions, WebSocket with streaming interactions, and FIX with institutional workflows. A stronger formulation sees each protocol as an organizer of interaction and, through that role, as a designer of local architecture.
Start with HTTP. Under RFC 9110, HTTP defines resource-oriented request-response semantics, methods, status codes, headers, and representations. It serves clear operations with strong structure: fetching historical bars, querying account state, placing an order, canceling an order, requesting configuration, and obtaining a health report. It also supports documentation with high clarity.


For internal trading services, that structure has high value. The stack gains clear contracts, reproducible input schemas, and rapid client generation.
HTTP also channels interaction through discrete exchanges. Applications that consume a continuous stream of trade events, order updates, heartbeats, or PnL deltas benefit from WebSocket. RFC 6455 defines a bidirectional protocol over TCP with an opening handshake and framed messages, built for two-way communication.

For example, Alpaca’s streaming documentation—I mean, the broker—presents trade, account, and order updates over WebSocket and highlights frame types across endpoints, plus authorization and stream subscription after connection. For a quant system, the implication is clear: WebSocket provides continuity, and continuity assigns responsibility. A persistent connection requires reconnect handling, duplicate control, interval recovery, subscription replay, sequence validation, and local buffering.
{
"action": "auth",
"key": "{YOUR_API_KEY_ID}",
"secret": "{YOUR_API_SECRET_KEY}"
}FIX addresses a different problem. The FIX Trading Community describes FIX as:
A standardized transaction language across the securities trade cycle, with message types aligned to steps such as quote request and new order, and with standardized fields as the building blocks.
That matters because institutional trading depends on precise business semantics across a workflow that spans indication, order, execution report, allocation, and post-trade reporting. FIX draws strength from a protocol that already speaks the language of the transaction. A modern retail or semi-professional quant stack may begin on other connectivity paths, yet it can still absorb the lesson: trading systems gain stability when message meanings stay explicit, durable, and tied to the lifecycle they govern.

The mathematics of transport stays simple. Let Ttotal denote end-to-end delay from the moment a signal becomes ready to the moment a fill event reaches local state. Then
A robust analysis evaluates the whole sum. In many implementations, Tbroker and Treconcile generate more variation than raw network travel time. Serialization, authentication, request signing, broker throttling, internal queuing, and local reconciliation can dominate the tails. Tail behavior matters more than averages because losses tend to concentrate there. A mean delay of 20 ms with a 95th percentile of 60 ms may fit one strategy and damage another whose edge concentrates in short-lived bursts.
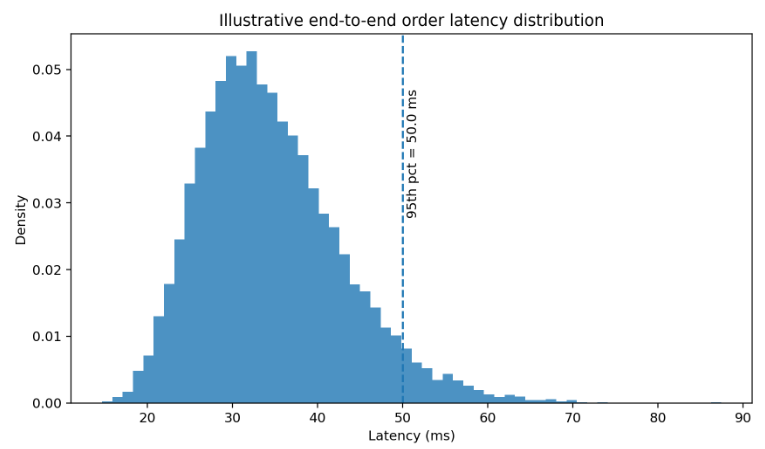
The histogram decomposes end-to-end order latency into plausible components and shows the aggregate distribution. The plot reveals that total latency is a sum of heterogeneous terms and that the tail can widen even when most components remain well behaved.
Risk and financial APIs limitation
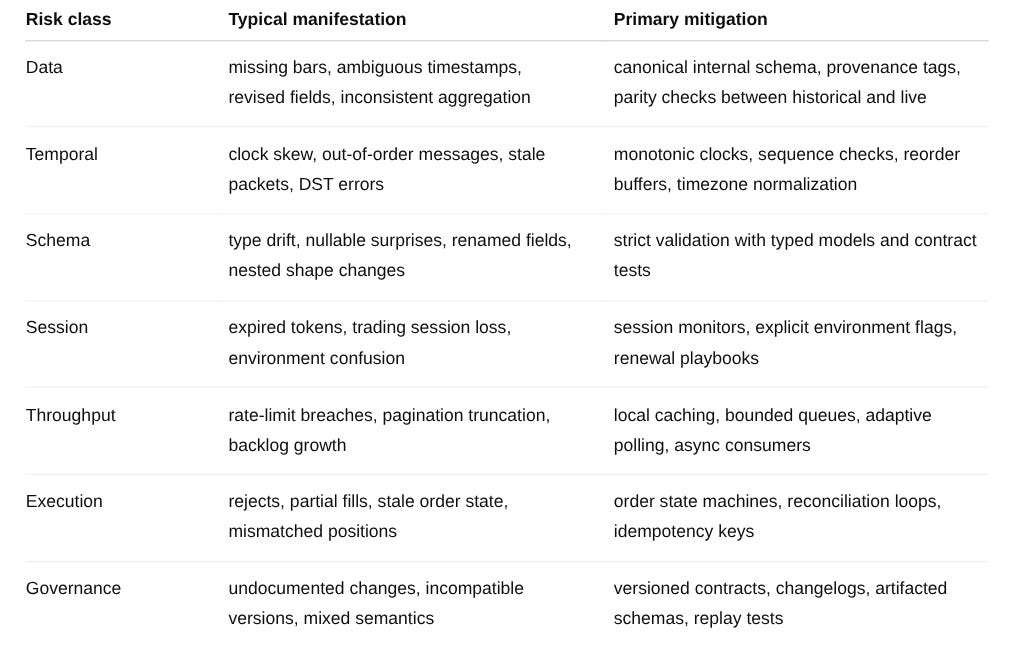
Once the API is treated as a formal component, the next task is classification. Risk in financial APIs represents a family of failure modes that interact. A useful taxonomy separates at least seven categories: data risk, temporal risk, schema risk, session risk, throughput risk, execution risk, and governance risk.
Data risk concerns what is transmitted. This includes missing fields, inconsistent bar construction, delayed corrections, undocumented transformations, and ambiguity about what a timestamp refers to. Is the bar timestamp the interval open, the interval close, or publication time? Are trades condition-filtered? Are odd lots included? Is volume consolidated at the same cadence in historical and live endpoints? Vendor documentation sometimes answers these questions, sometimes not. The point is that the risk exists even when the feed looks clean. A clean feed can still describe the wrong object for the strategy.
Temporal risk concerns when the data is available and in which order. Clock drift between client, broker, and data vendor is the obvious part. More subtle is the distinction between event time and arrival time. A message may encode one time but arrive at another. Streaming systems can also deliver temporary disorder. If the strategy assumes a total order while the transport offers only a best-effort order plus reconnect recovery, then the local state machine must restore order or at least detect that order was broken.
Schema risk concerns how the data is structured. An endpoint that changes a field name, adds a nullable attribute, changes a numeric type from integer to string, or alters nesting may be perfectly legal at the API level and still break live trading. This is why type validation libraries matter.
Session risk is operational but critical. Authentication expiry, refresh tokens, signed requests, environment separation, and broker session exclusivity determine whether the trading path remains live. Some APIs are quite clear that trading-enabled sessions have different restrictions than generic access, including brokerage-level single-session limits.
Throughput risk includes rate limits, quotas, pagination, backpressure, and resource exhaustion. This category is often underestimated by quants who work first in notebooks. Yet the feasible research surface is shaped by what the API allows. If a cross-sectional study requires more requests per minute than the provider permits, then the signal either needs a different collection design, a local cache, a licensed feed, or a narrower universe. Throughput is a constraint on the set of admissible strategies.
Execution risk concerns the gap between request acceptance and actual market interaction. Here a good example of why this matters: “the order object has identifiers, statuses, and a lifecycle that can be queried after placement. That is useful, but it also confirms the obvious point that the initial placement call is only one transition in a larger process. SEC routing and execution disclosures exist because the path from broker to venue materially affects outcomes”. In trading, the request path and the execution path should never be conflated.
Governance risk covers versioning, deprecation, environment drift, and organizational ambiguity. An internal API that is undocumented, lacks version tags, or mixes research-only fields with live-only fields can corrupt an otherwise sound strategy. Governance is what keeps the contract stable long enough for experiments to be comparable.
A convenient formalization is to model observed system risk as the union of these categories:
Each component can be associated with observables: gap counts, duplicate counts, validation failures, authentication renewals, request rejections, order rejects, and contract-version mismatches. The important point is that API risk becomes measurable only after categories are explicit.
The table below compresses this pitfalls:
Throughput deserves one extra comment because it changes research conclusions. Assume that trade opportunities survive for a characteristic time constant τ and that the system polls every Δ units of time rather than consuming a push stream. A rough first-order miss model is:
This formula is for illustrative purposes. It says that when opportunity duration is short relative to the observation interval, miss probability rises quickly. Coarser polling changes the distribution of observed opportunities. The picture below visualizes that relationship:
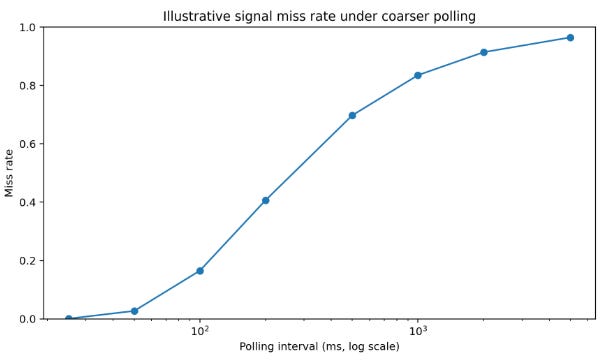
Quants often frame API problems as reliability problems. They are also selection problems. The feed, the protocol, and the quota choose which events you ever get the chance to model. That means a strategy discovered under one data-access regime may not even be defined under another. Once this is understood, the response becomes sharper.
Historical-live non-equivalence and data reconstruction error
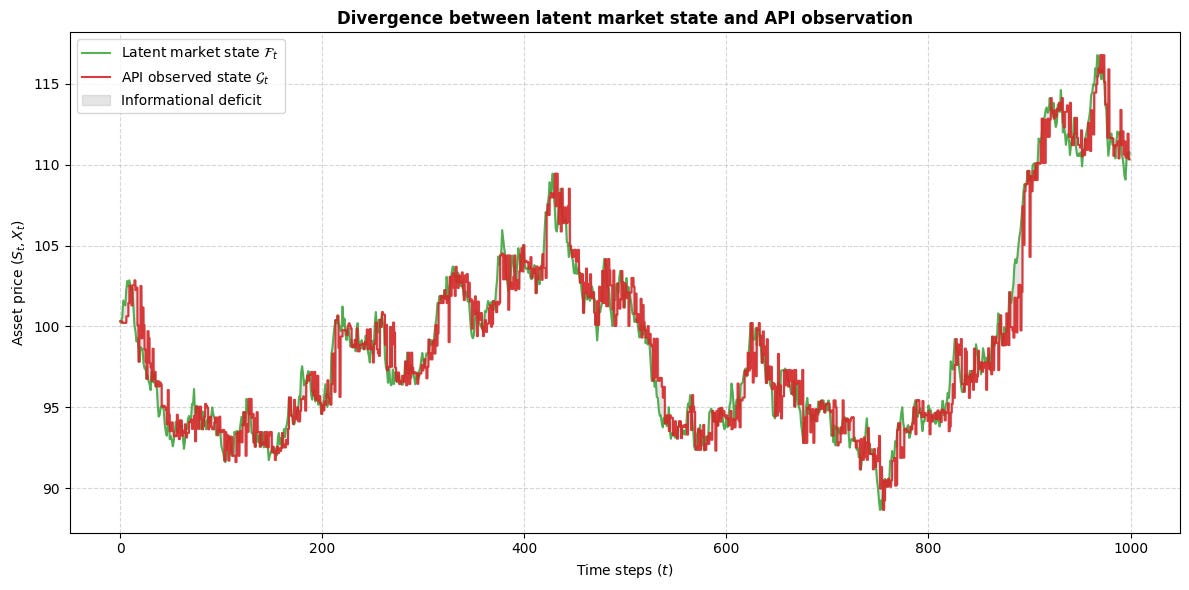
Historical endpoints and live endpoints are seldom equivalent in the strict sense required by causal research. They may deliver related objects, but related is not enough. Historical data is often cleaned, deduplicated, repaired, aligned to bar boundaries, and packaged into stable records. Live data is incremental, provisional, and susceptible to temporary disorder. A strategy that learns on one and trades on the other inherits a reconstruction problem.
There are at least four sources of non-equivalence:
The first is finalization: Historical bars tend to be final objects. Live bars, unless the provider specifically publishes only completed intervals, may be in progress.
The second is correction policy: Historical vendors can revise prior records after exchange corrections or internal data-quality routines. Live systems receive the pre-correction path and may or may not later receive explicit correction messages.
The third is aggregation method: A historical endpoint may aggregate on server-side rules that differ from a client’s local reconstruction from trade ticks.
The last one is delivery semantics: Historical data is fetched as a completed array. Live data is delivered as a stream in which messages can be delayed, duplicated, or arrive after reconnect.
Any research process should ask a simple but uncomfortable question: is the historical object used in research reproducible from the live stream using only information available at the time? If the answer is no, then the strategy is at risk of hidden lookahead or deployment drift. Sometimes the mismatch is harmless. Often it is not. Opening-range logic, event-triggered strategies, and execution-sensitive systems are especially vulnerable because they depend on exact temporal boundaries.
One clean way to formalize the problem is to define a reconstruction operator G that maps a live stream path into a bar or state record:
The historical dataset supplies bthist. The research assumption that often goes unstated is that bthist = btlive_recon. This is rare. The true object of concern is the reconstruction error:
A strategy that is stable under small δt may survive deployment. A strategy that changes sign, entry timing, or position size under small δt may lose money even if the backtest looks good. This is one reason why mature groups insist on replay tests. They record live messages, reconstruct the internal state offline, and compare it with both the production decision log and the historical vendor view.
Out-of-order delivery is a particularly sharp example. Suppose messages carry event timestamps ei but arrive at times ai. A client that sorts by arrival time instead of event time assumes that sign(ai - aj) equals sign(ei - ej) for all pairs. That assumption is false in many real networks. Once it breaks, local bars, rolling indicators, or event-triggered conditions may shift. The correct response is to build reordering logic with bounded buffers and explicit policy for what to do when order cannot be restored with confidence.
Here is a minimal sketch of such a guard:
from dataclasses import dataclass
from heapq import heappush, heappop
@dataclass(order=True)
class MarketEvent:
seq: int
ts_event_ns: int
payload: dict
class ReorderBuffer:
def __init__(self, max_gap: int = 32):
self.expected = 0
self.max_gap = max_gap
self.heap = []
def push(self, event: MarketEvent):
if event.seq < self.expected:
return [] # duplicate or stale replay
heappush(self.heap, event)
out = []
while self.heap and self.heap[0].seq == self.expected:
out.append(heappop(self.heap))
self.expected += 1
if self.heap and self.heap[0].seq - self.expected > self.max_gap:
raise RuntimeError("sequence gap too large")
return outThe point of the snippet is to show the shape of the invariant. Local state should advance only when sequence integrity is acceptable. If the gap exceeds a declared tolerance, the client should raise an incident, resubscribe, or rebuild state from a safer source.
The next plot shows the operational consequence of delayed observations on a simple synthetic crossover-style entry. The delayed observation sees the same price path later and enters later. The lesson is that even modest observation delay can transform entry timing in a way that a clean historical backtest never exposed.

A common response is to smooth the signal until these issues disappear. That can help, but it does not solve the identification problem. If the strategy only works when final corrected bars are used, then the strategy depends on a state that may not exist in live trading.
First, define decision-time objects. Second, test historical-live parity by replaying captured live streams into the same internal schemas used in production. Third, store provenance metadata with every derived bar or indicator: source, reconstruction mode, timezone, sequence completeness, and whether the object is provisional or finalized. Fourth, make non-equivalence visible in research by introducing uncertainty envelopes. If a signal flips under plausible reconstruction perturbations, that signal should not be promoted.
Execution state machines and order routing
The industry still tolerates expressions like: “send the order”, “the order is in”, “the order got filled”. For software, these phrases hide critical distinctions. For PnL, they hide money. However, execution should be modeled as a state machine.
A request to place an order is only a statement of intent until the broker acknowledges it. The acknowledgment is not yet a fill or the fill may be partial. The remaining quantity may rest, cancel, expire, or be modified by subsequent logic. Some APIs reflect these transitions in a REST resource that can be queried after placement; others also emit asynchronous trade or order updates over a stream; sometimes users place, monitor, and cancel orders through the Trading API, and that order identifiers and status objects support later inspection. The best approach is to maintain two separate layers: account and order routing. That separation is healthy because it prevents one channel from pretending to be the whole lifecycle.
Okay, let’s talk about the second one: routing. SEC rules on order execution and order routing disclosure exist because the path an order takes after leaving the customer-facing system affects economic results. A retail API client sees only part of the venue-level journey, and the system designer should treat that journey as relevant. Even if the internal API abstracts away venue detail, it should preserve enough state to distinguish user intent, broker acceptance, downstream routing outcome, and final position reconciliation.
A minimal lifecycle can be written as:
with additional branches for rejected, canceled, expired, and replaced. Not every broker surfaces each branch in the same way. The internal system should anyway. Doing so has three advantages. First, it prevents false certainty. Second, it enables reconciliation. Third, it supports simulation. A sound backtest represents the full state machine between signal and filled position, because those intermediate transitions reveal failure modes that materially shape PnL.
Consider expected execution price. A crude but useful decomposition is:
Here Pref is a chosen reference price, Squeue captures queue-position effects and spread interaction, Slatency captures adverse movement while the order is in flight, Simpact captures self-induced price movement for non-negligible size, and Sfees captures commissions, exchange fees, rebates, and financing where relevant. Many prototype systems focus on Slatency and ignore the rest. That is tolerable for a toy simulator, but not for a research workflow that wants to claim tradability. Even a simple simulator should at least model partial fills, expiry, and side-dependent slippage under volatility.
An internal order model should therefore separate three objects:
OrderIntent: what the strategy wants.
BrokerOrderState: what the broker has acknowledged and how it has evolved.
PositionLedgerEntry: what the portfolio believes happened after reconciliation.
Conflating them creates the classic bug where the strategy believes it is flat because its own intent was to exit, while the broker still shows a partially open quantity.
A minimal type sketch might look like this:
from enum import Enum
from pydantic import BaseModel, Field, field_validator
from typing import Optional
class OrderSide(str, Enum):
BUY = "BUY"
SELL = "SELL"
class OrderState(str, Enum):
INTENT = "INTENT"
ACCEPTED = "ACCEPTED"
WORKING = "WORKING"
PARTIALLY_FILLED = "PARTIALLY_FILLED"
FILLED = "FILLED"
REJECTED = "REJECTED"
CANCELED = "CANCELED"
EXPIRED = "EXPIRED"
class OrderIntent(BaseModel):
client_order_id: str
symbol: str
side: OrderSide
qty: float = Field(gt=0)
limit_price: Optional[float] = Field(default=None, gt=0)
class BrokerOrderState(BaseModel):
client_order_id: str
broker_order_id: Optional[str] = None
state: OrderState
filled_qty: float = Field(ge=0)
avg_fill_price: Optional[float] = None
@field_validator("avg_fill_price")
@classmethod
def positive_price_if_present(cls, v):
if v is not None and v <= 0:
raise ValueError("avg_fill_price must be positive")
return vThe exact fields can be adjusted. Once these objects are defined, live logic becomes cleaner. Reconciliation compares the latest broker state with the internal ledger. Simulation advances through legal states instead of jumping from signal to fill. Risk logic defines kill-switch conditions in terms of state divergence, not only PnL.
Quants often focus on price improvement as the hard part of execution. In many systems, the hard part is state certainty. A robust system determines with high confidence whether an order is live, whether a cancel request succeeded, and whether a partial fill changed net exposure. Alpha only matters when the process itself is reliable. The real objective is to build an execution engine whose states are clear enough that later improvements rest on solid assumptions.
This leads to prototype API design. Even at the prototyping stage, order endpoints benefit from idempotency, accept client-generated identifiers, distinguish acceptance from fill, and expose a machine-readable state model. Internal consumers rely on structured state as the source of truth. Human-readable logs still help, but they support the contract rather than define it.
The external side of the problem therefore becomes clear: financial APIs present data and orders as evolving states carried through channels with meaningful semantics. The constructive response is to assign those states formal names and transitions. Once that structure is in place, the internal API becomes the stable surface across which research, simulation, and live code remain aligned.

Simulation and live trading
One script uses the same field names as the next, timezones remain consistent across services, the execution engine works with normalized order states, the backtester uses the same fill object as live trading, and the monitoring service reads position exposure from a shared contract rather than reconstructing it from logs. That is manageable at small scale and essential at medium scale. The solution is to design an internal API.
The main purpose of an internal API is contract preservation. Research, paper trading, backtesting, and live services should consume and emit the same conceptual objects even when their data sources differ. If one system produces Signal(direction, generated_at, horizon, confidence) and another expects alpha_score, entry_ts, and weight_hint, the boundary needs stronger alignment. The internal API creates that alignment by enforcing shared names, units, valid ranges, and temporal interpretation.
A sensible contract design starts with five invariants:
Causality: Every object that can influence a decision carries a timestamp or event key that identifies when it became admissible. This includes bars, features, signals, risk checks, and order updates. With that structure in place, replay testing becomes meaningful.
Provenance: A bar is more than OHLCV. It carries information about whether it came from vendor history, live reconstruction, a synthetic resampler, or a replay archive. That small field turns future debugging into straightforward engineering.
State separability: Data objects, signal objects, order-intent objects, broker-state objects, and portfolio-ledger objects each remain distinct. This separation keeps assumptions from leaking across modules and preserves clarity at the interfaces.
Versioning: Schemas evolve, and they should evolve explicitly. A
schema_versionfield together with artifacted OpenAPI snapshots provides inexpensive and reliable protection.Idempotency: Commands that change state, especially order-related commands, should support replay without accidental duplication. Client order IDs provide the standard mechanism.
These invariants can be supported with concise Pydantic models. Here is a small example:
from datetime import datetime, timezone
from pydantic import BaseModel, Field, field_validator
from typing import Literal
class Bar(BaseModel):
schema_version: str = "1.0"
source: Literal["vendor_history", "live_recon", "replay"]
symbol: str
ts_open: datetime
ts_close: datetime
open: float = Field(gt=0)
high: float = Field(gt=0)
low: float = Field(gt=0)
close: float = Field(gt=0)
volume: float = Field(ge=0)
@field_validator("ts_open", "ts_close")
@classmethod
def enforce_timezone(cls, v: datetime):
if v.tzinfo is None:
raise ValueError("timestamps must be timezone-aware")
return v.astimezone(timezone.utc)
class Signal(BaseModel):
schema_version: str = "1.0"
generated_at: datetime
symbol: str
direction: int
horizon_s: int = Field(gt=0)
confidence: float = Field(ge=0.0, le=1.0)
model_tag: strThe snippet already delivers three concrete benefits. Invalid states fail early, schemas become inspectable by both humans and machines and, client libraries can be generated or written against a stable description rather than inherited through oral tradition.
The internal API also makes research and live mode comparable by design. A strong pattern places all market-data acquisition behind adapter interfaces and exposes only canonical internal models to the rest of the stack. The rest of the code then works with the same objects whether bars came from Alpaca, IBKR, a CSV archive, a replay file, or MetaTrader. Sources are not interchangeable, but their specific oddities belong at the boundary, where they can be normalized, instead of spreading through the strategy codebase.
Do you know what is premature? To build a large platform before the contracts are understood. A lean internal API can live inside a single FastAPI application with a few strict models and a small set of endpoints. What matters is that the contracts are defined before the complexity arrives.
A practical minimal endpoint set for a quant prototyping API includes /health, /bars, /signal/run, /orders/simulate, /orders/submit, /positions, /portfolio/state, and /backtest/run. Each one benefits from typed inputs and outputs, deterministic validation, and a precise statement of time semantics.
The internal API also supports replay, allowing a team to verify that the object evaluated in research matches the object the live system would have seen. An endpoint that consumes archived messages and emits canonical internal states often adds more value than a second optimization endpoint. Little by little we will be building things like this: