

[WITH CODE] Optimization: Combinatorial Purged Cross Validation for optimization
Parameter optimization part II

Table of contents:
Introduccion.
Is robustness pure fiction?
Risks and limitations of this approach.
Model specification and parameter dependency.
The illusion of optimal.
The failure of standard CV in finance.
Probabilistic framework.
The Probabilistic Sharpe Ratio and robustness metrics.
A weighted consensus for stability.
Before you begin, remember that you have an index with the newsletter content organized by clicking on “Read full story” in this image.

Introduccion
Traditional grid or Bayesian searches conducted on a single path reward parameters that overfit to this specific historical path. This inflates performance metrics through selection bias and temporal leakage. Combinatorial Purged Cross-Validation (CPCV) addresses this flaw by generating a multitude of chronology-respecting train-test partitions. Crucially, it purges any overlapping information, ensuring that each out-of-sample evaluation is statistically independent of its training window.
The outcome is not a single performance score per parameter set, but rather an empirical distribution of out-of-sample outcomes. This distribution reveals the stability—or lack thereof—of the strategy across a diverse set of plausible historical paths. Consequently, the objective shifts from maximizing a point estimate to identifying robust parameter regions. We seek plateaus, not peaks: parameters that remain performant under numerous counterfactual scenarios are preferred over those that are optimal in one specific history but brittle elsewhere.
This conceptual reframing—from optimization to robustness—establishes the foundational framework for the subsequent analysis. In fact, today we're going to look at a different application than the classic use of CPCV.
Although the application context we'll be using has changed, you can find the classic uses here::

Ok, let’s continue! A common approach to this problem is to test a range of parameter values against historical data and select the combination that yields the highest performance. While intuitively appealing, this process is fraught with peril. The primary risk is selection bias, a specific and insidious form of overfitting. By selecting the best-performing parameter set from a multitude of trials on the same historical data, we are often just fitting the model to the specific noise and random fluctuations of that particular history. The chosen optimal parameter is unlikely to be truly optimal for future, unseen data. It is merely the parameter that best memorized the past.
The danger of using a technique like CPCV without a deep understanding of its purpose is that it can be misconstrued as just another, more complex, way of finding the peak of a profit-and-loss curve. One might run thousands of combinatorial paths, find the parameter value that appears most frequently among the top performers, and declare victory. This, however, is a subtle but critical failure. We are not looking for the best performance, but the most stable performance. The risk is overfitting the validation process itself, finding a parameter that looks robust by sheer chance across a specific set of random data splits.
Consequently, a single optimal parameter derived from a single historical path is a statistical illusion. The conflict is between our innate desire for a single, definitive, correct answer and the stark reality of a stochastic world where no such answer exists. This requires a fundamental shift in perspective: from optimization to robustness. The goal is not to find the parameter that would have been the best, but to find a parameter that is likely to be good enough across a wide range of plausible future scenarios. This shift is the intellectual engine driving the adoption of sophisticated validation techniques like CPCV.
Is robustness pure fiction?
If you have created a model, it is normal to have at least one parameter. And this is where the first problem comes in: The necessity of finding robust parameters is a prerequisite for survival in financial markets.
A strategy whose performance is highly sensitive to small changes in its parameters is inherently fragile. If a strategy is profitable with a 20-day lookback but incurs losses with a 19-day or 21-day lookback, its observed profitability was likely a statistical artifact, a result of overfitting to a specific frequency in the historical noise spectrum. The market does not operate on integer-day cycles with knife-edge precision. A truly robust strategy, one that has captured a genuine economic or behavioral anomaly, should exhibit a degree of performance stability across a neighborhood of similar parameter values.
This meta-stability is what provides confidence that the strategy's logic is sound. Therefore, the search for optimal parameters is not merely about maximizing a backtested performance metric; it is a search for evidence that our model is not a fluke.
The obstacles to achieving this are significant and scale poorly. Even when optimizing a single parameter, the primary challenge is the trade-off between bias and variance. If we use too little data for training (high bias), the model won't capture the underlying signal. If we use too much data and test too many parameter variations (high variance), we risk fitting to noise. This problem is amplified exponentially when we consider multiple parameters—a phenomenon known as the curse of dimensionality.
Consider a strategy with just three parameters, each with ten possible values. The total number of combinations to test is 103=1000. With five such parameters, it explodes to 105=100,000. The computational burden becomes immense, but more critically, the probability of finding a seemingly brilliant result purely by chance (a "false positive") approaches certainty. For a sufficiently large search space, the maximum of a set of random variables will almost always appear impressively high. This is why any of us need a statistically sound validation framework, to protect us from our own data-mining capabilities.

Risks and limitations of this approach
The logic of CPCV is significantly more complex than a standard backtest. Implementing the purged splitting, managing the combinatorial paths, calculating performance distributions, and aggregating results requires careful coding. This complexity creates a high risk of bugs that are not immediately obvious. For example:
An off-by-one error in the purging logic could re-introduce data leakage in a subtle way.
Incorrectly handling the indices for train/test splits could lead to lookahead bias.
Bugs in the calculation of higher-moment statistics (skew, kurtosis) could invalidate the PSR results.
The most dangerous aspect is that these bugs often result in silent failures: the code runs without crashing and produces a result, but that result is fundamentally flawed, leading to a false sense of confidence in a parameter or strategy.
Perhaps this is not the worst; there are more dramatic blunders, such as statistical or methodological ones. These risks are more subtle and relate to the statistical assumptions and limitations of the method itself.
CPCV is designed to prevent overfitting a parameter to a single historical path. However, if a researcher tests dozens of different strategy ideas (different models, different indicators, different rules) on the same dataset, all using a rigorous CPCV process, they will eventually, by pure chance, find an idea that looks robust. This is overfitting the research process or meta-overfitting. The researcher is selecting the luckiest outcome not from a set of parameters, but from a set of strategies. CPCV cannot protect you from this. The only defense is a disciplined research process, a strong economic rationale for each strategy, and the use of a final, untouched hold-out dataset.
The CPCV process itself has several key hyperparameters, and the final robust parameter can be sensitive to their settings:
n_splits: The number of combinatorial paths. If this is too low (e.g., < 100), the resulting performance distributions will be unstable and noisy. The 10th percentile metric will not be reliable.train_size_pct/test_size_pct: This defines the bias-variance trade-off of the validation itself. Very short test sets will produce noisy performance metrics (high variance). Very short training sets will lead to poorly fitted models in each fold (high bias), underestimating the strategy's true potential.purge_size: This is not a parameter to be guessed. It must be set based on the maximum horizon of your signal's dependency on future data. Setting it too small will fail to prevent leakage.
CPCV's core strength is testing a parameter against a wide combination of past market regimes. However, it operates on the fundamental assumption that the future will be a recombination of the past. It cannot anticipate a true structural break or a novel market regime with dynamics completely unseen in the historical data (e.g., a shift from inflationary to deflationary macro environments, or the introduction of a game-changing technology). A parameter found to be robust on 2000-2025 data is not guaranteed to be robust in a future regime that is fundamentally different from anything in that period.
CPCV requires a sufficiently long time series to be effective. If you are working with an asset that has limited history (e.g., a recently launched ETF or a cryptocurrency), CPCV is often impractical. The train and test windows would be so short that any performance metric calculated on them would be statistically meaningless. Attempting to use CPCV on insufficient data will produce unstable and unreliable results.

Besides we need to take into account the risks related to how the researcher interprets the output of the CPCV process, potentially leading to flawed conclusions.
The complexity and computational intensity of CPCV can create a powerful illusion of objectivity. Because the process is so involved and data-driven, it's easy to blindly trust the number it produces. A researcher might find that N=31 is the robust parameter and stop thinking, ignoring the fact that the underlying economic thesis for the strategy makes no sense at that frequency. The quantitative output must always be subject to qualitative oversight and economic reasoning.
The framework detailed in the paper focuses on the 10th percentile of the PSR distribution. This is an excellent metric for a strategy that aims for consistent, steady returns. However, it may be the wrong metric for other types of strategies. For example:
Crisis alpha / tail hedging strategy: Such a strategy is designed to lose small amounts of money most of the time and make very large gains during market crashes. Optimizing for the 10th percentile PSR would likely discard such a strategy. For this, one should analyze the 1st or 5th percentile of the returns distribution, not the PSR—that we will be using for the sake of the article.
High-risk, high-reward strategy: For a strategy where the goal is to maximize upside, focusing on the 90th percentile of the distribution might be more appropriate. The key risk is misaligning the statistical metric used for optimization with the stated economic objective of the trading strategy.

Model specification and parameter dependency
To explore the nuances of parameter optimization, we must first define a model to operate on. For this exercise, we'll use a simple, yet effective, breakout strategy. The logic is straightforward: a signal is generated when the current price exceeds the maximum (for an upside breakout) or falls below the minimum (for a downside breakout) of a preceding number of periods. This number of periods is our key parameter, which we'll call the lookback window, denoted as N.
Mathematically, for a given price series P={p1,p2,...,pt}, the conditions for generating a signal at time t are:
Upside breakout signal (sell): pt>Ht(N)
Downside breakout signal (buy): pt<Lt(N)
This model, while simple, encapsulates the fundamental challenge. The performance of the strategy is entirely dependent on the choice of N. A small N will make the model highly sensitive and prone to generating many signals, potentially capturing short-term moves but also getting whipsawed by noise. A large N will make the model less sensitive, generating fewer signals that correspond to more significant, sustained trends, but it might miss shorter-term opportunities and react slowly to market changes.
Let's implement this in Python.
import numpy as np
class BreakoutModel:
"""
A generic model to detect breakouts in a price series using NumPy.
An 'up' direction breakout occurs when the current price exceeds the max of the previous N bars.
A 'down' direction breakout occurs when the current price falls below the min of the previous N bars.
"""
def __init__(self, window: int = 20, direction: str = 'up'):
"""
Initializes the breakout model.
:param window: The lookback window (N) for calculating the max/min.
:param direction: 'up' for upside breakouts, 'down' for downside breakouts.
"""
if not isinstance(window, int) or window <= 0:
raise ValueError("window must be a positive integer.")
if direction not in ('up', 'down'):
raise ValueError("direction must be 'up' or 'down'")
self.window = window
self.direction = direction
def predict(self, data: np.ndarray) -> np.ndarray:
"""
Generates trading signals based on the breakout logic.
:param data: A NumPy array of prices.
:return: A NumPy array of signals (1 for buy, -1 for sell, 0 for no signal).
"""
data = np.asarray(data, dtype=float)
n_samples = len(data)
signals = np.zeros(n_samples, dtype=int)
# We can only start generating signals after the first full window
for i in range(self.window, n_samples):
window_slice = data[i - self.window : i]
if self.direction == 'up':
# An upside breakout is a signal to sell (e.g., shorting volatility)
if data[i] > np.max(window_slice):
signals[i] = 1
else: # direction == 'down'
# A downside breakout is a signal to buy (e.g., going long volatility)
if data[i] < np.min(window_slice):
signals[i] = -1
return signalsThe code directly translates our mathematical definition. It iterates through the variable with predictive power and, for each point after the initial window, checks for the breakout condition.
The illusion of optimal
The most common and catastrophic mistake in parameter selection is naive in-sample optimization, a practice more accurately described as curve-fitting. This involves running a backtest for every possible parameter value in a given range on the entire historical dataset and selecting the value that produces the best result. The outcome is a parameter that is perfectly tailored to the specific quirks and random noise of that historical data, and almost certainly suboptimal for the future.
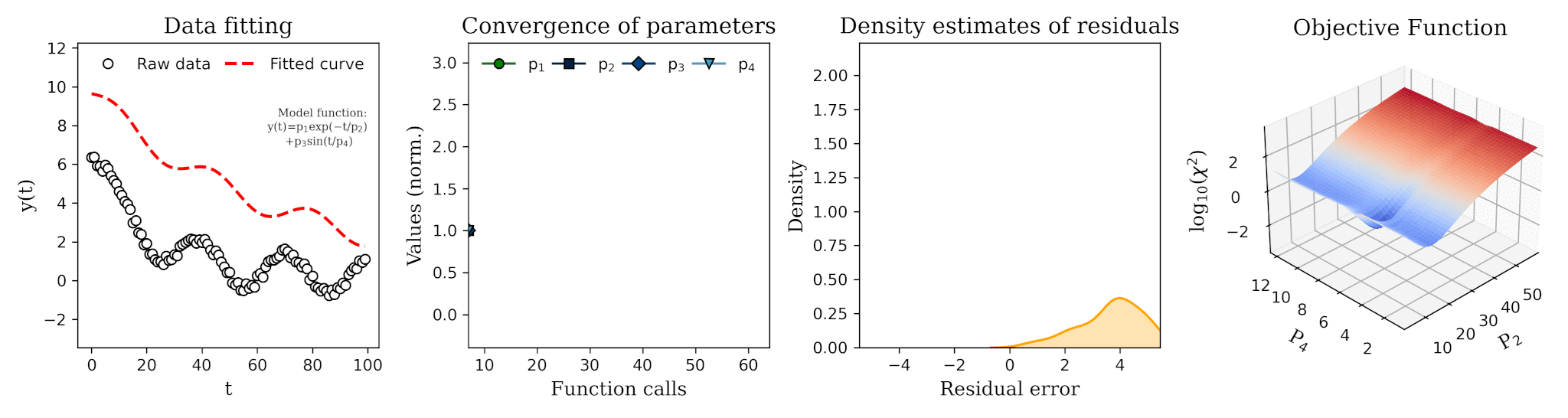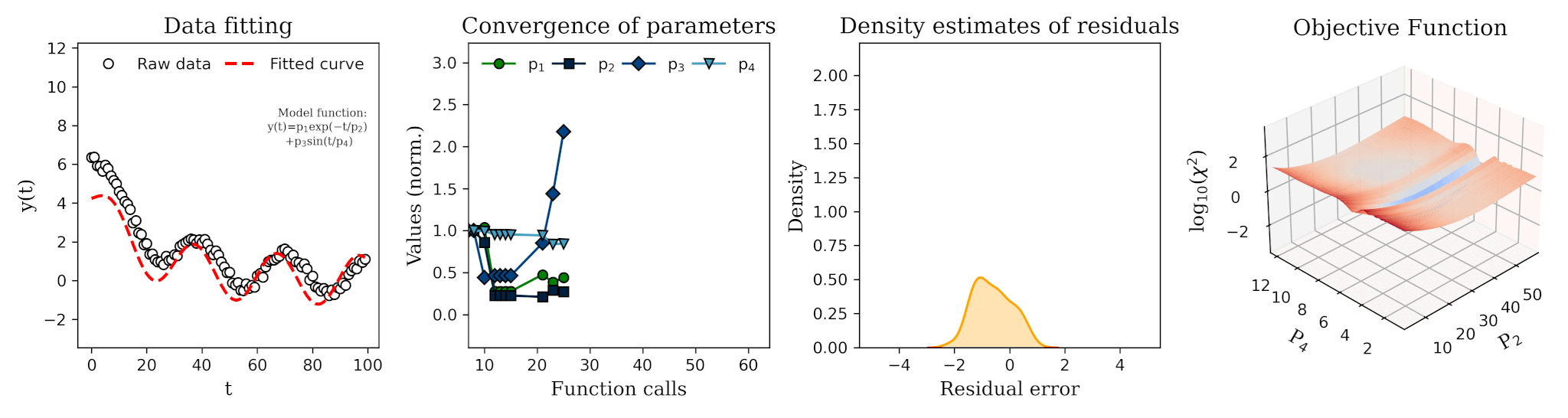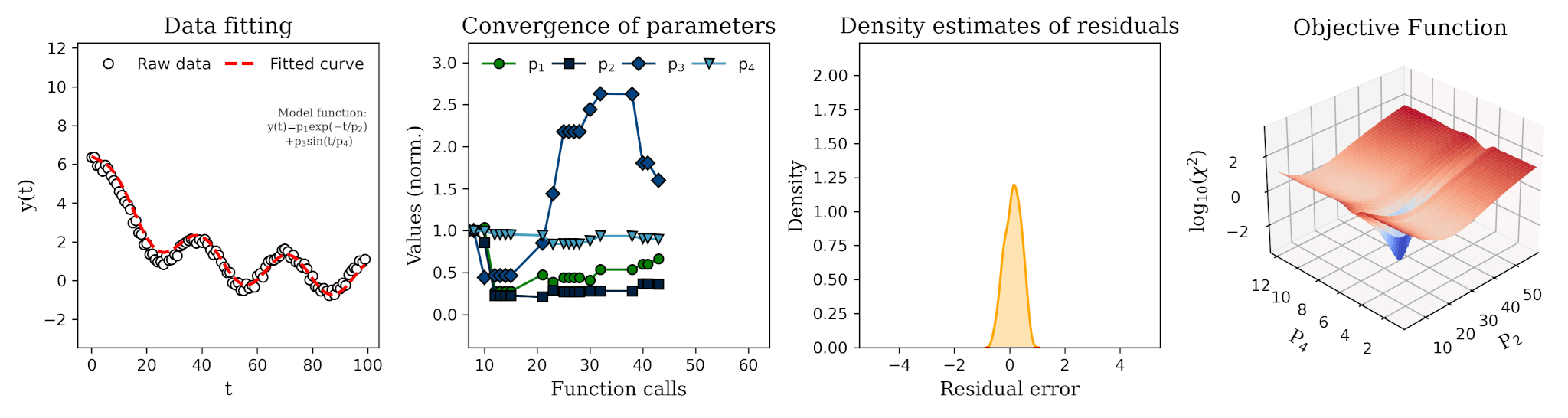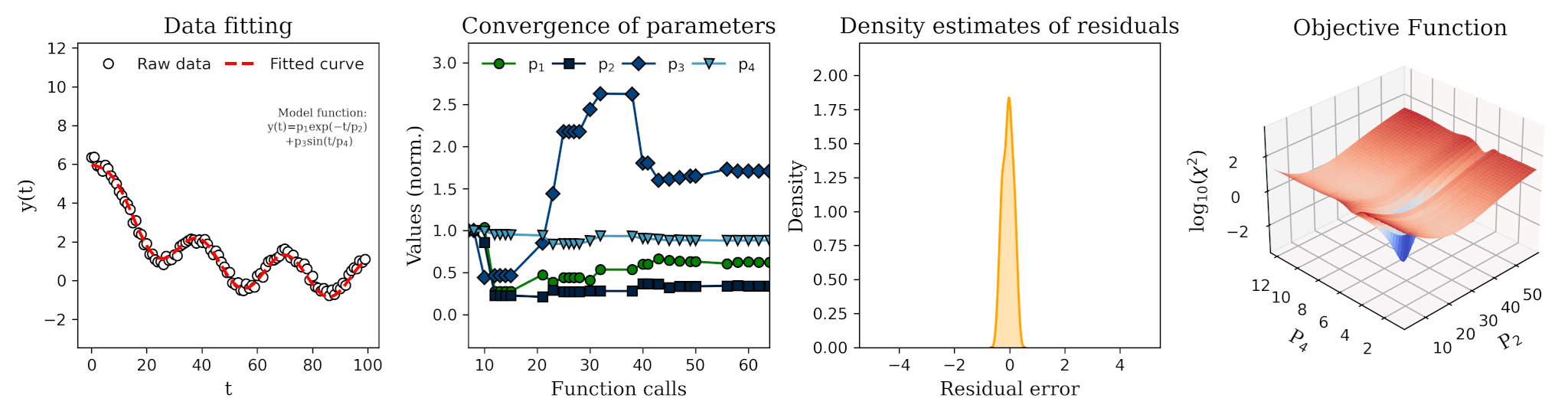
The probability of backtest overfitting is not just a qualitative concern; it can be quantified. Let N be the number of independent trials (e.g., the number of different parameter sets tested). If each trial's performance is a random variable, the expected value of the maximum performance across all trials will be significantly higher than the expected value of any single trial. This difference grows with N. By selecting the maximum, we are systematically selecting for positive estimation error. A metric like the Deflated Sharpe Ratio attempts to correct for this by estimating what the Sharpe Ratio would be if the selection bias were removed. Its calculation involves the variance of the tested Sharpe Ratios and the size of the trial set, effectively penalizing strategies that arise from extensive data mining.
Let's demonstrate this overfitting trap visually. We will split a historical price series into two parts: an in-sample (IS) set (e.g., the first 70% of the data) and an out-of-sample (OOS) set (the remaining 30%). We will perform a naive optimization on the IS set to find the best parameter N, and then we will observe the performance of all tested N values on the OOS set.
We will need these helpers:
def backtesting(price: np.ndarray, signals: np.ndarray) -> np.ndarray:
price_diff = np.diff(price, prepend=price[0])
signals_shifted = np.roll(signals, 1)
signals_shifted[0] = 0
strategy_returns = signals_shifted * price_diff
return np.cumsum(strategy_returns)
def model_signal_generator(series: np.ndarray, N: int) -> np.ndarray:
model_buy = BreakoutModel(window=N, direction='down')
model_sell = BreakoutModel(window=N, direction='up')
signals = model_buy.predict(series) + model_sell.predict(series)
position = 0
final_signals = np.zeros_like(signals)
for i in range(len(signals)):
if signals[i] != 0:
position = signals[i]
final_signals[i] = position
return final_signals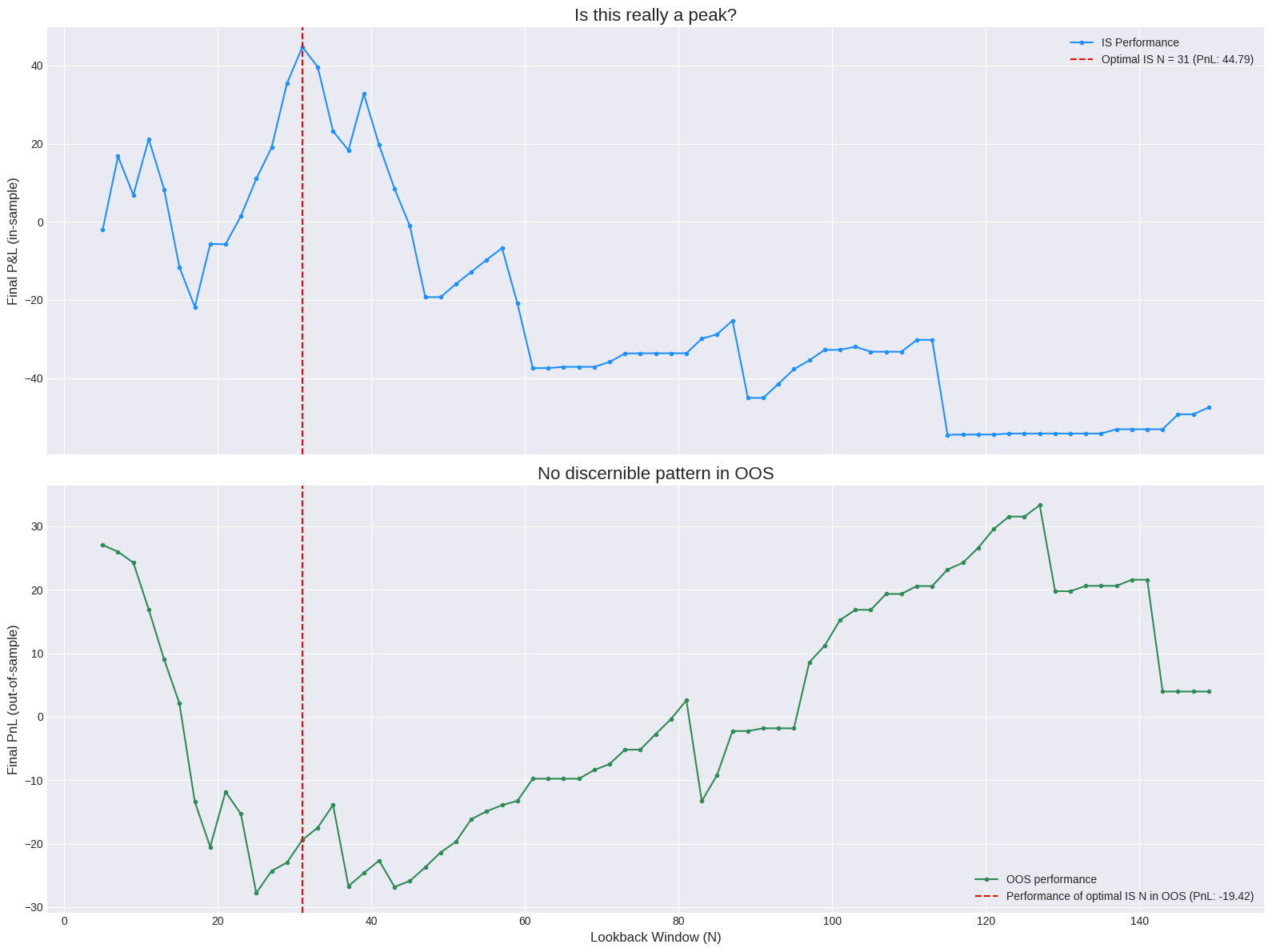
The visual evidence is damning. The top plot shows a classic, seductive optimization curve with a clear peak. An unsuspecting analyst would confidently select N=31. The bottom plot reveals the truth. The out-of-sample performance curve is a noisy, random-looking series with no discernible peak. The parameter that was optimal in-sample is unremarkable out-of-sample; its performance is mediocre, close to the average. This experiment starkly illustrates that the peak found in-sample was an artifact of fitting to noise. Maximizing performance on a single pass of the data tells us nothing about a parameter's robustness; in fact, it often leads us to select the least robust, most overfit candidates.