


Table of contents:
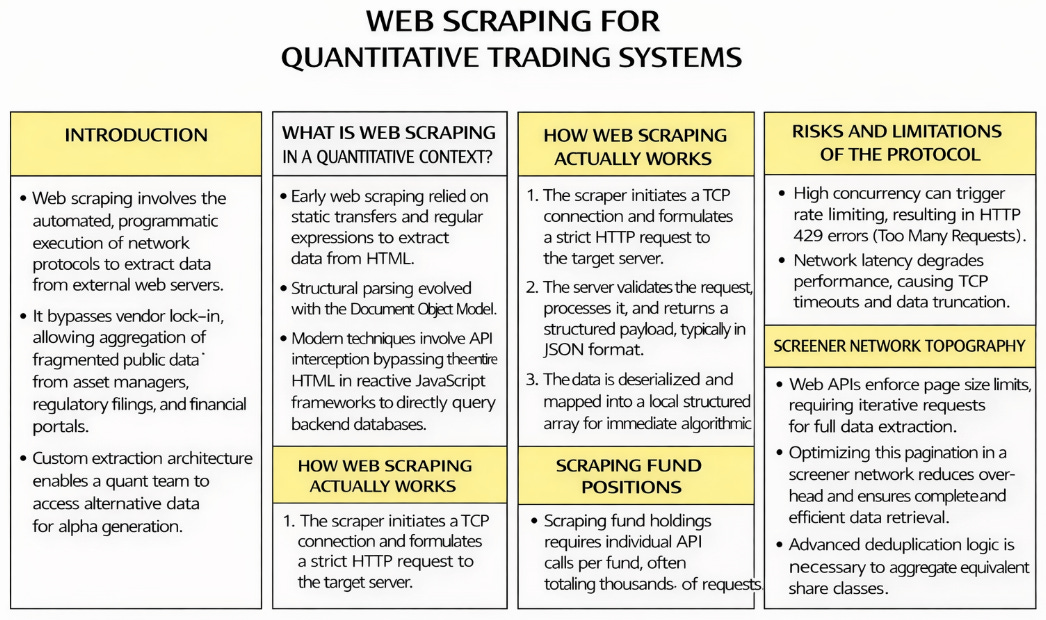
Introduction.
What is web scraping in a quantitative context?
Where does it come from?
How web scraping actually works.
Risks and limitations of the protocol.
Screener network topography.
Scraping fund positions.
Before you begin, remember that you have an index with the newsletter content organized by clicking on “Read the newsletter index” in this image.

Introduction
In fund research, the input that matters most is simple: what stocks are inside the funds right now, and in what weight. Without that look-through layer, fund momentum, category rotation, or risk exposure becomes a label-driven proxy.
We are going to construct and execute a systematic fund scraping operation. The explicit objective of this architecture is to expose what underlying stocks these otherwise opaque mutual funds and ETFs are holding.
If you intend to calculate true portfolio variance, isolate specific factor exposures, or detect hidden beta overlap across multiple assets, you must possess the exact equity constituents and their precise percentage weightings for every fund in your cross-section. Without ticker-level resolution, you might allocate capital to two distinct Diversified Value funds that both hold massive, highly correlated positions in the exact same mega-cap technology stock.
So, we will engineer a deterministic data pipelineto get a clean, structured JSON. The architecture we are deploying will execute in distinct, logical phases:
We will intercept the provider’s APIs to extract the core fund metadata and historical return vectors.
We will utilize concurrent, threaded I/O operations to query the global holdings API.
We will map this extracted data into memory-contiguous C-arrays.
We will apply algorithmic deduplication using tokenized lexical analysis and tuple signatures to eliminate share class multicollinearity.
The final output of this operation will be a sanitized, lightweight matrix of unique portfolios, ready for immediate ingestion into our engine.
What is web scraping in a quantitative context?
To understand the architecture we build for trading, we must first define what web scraping is at a fundamental, computational level. In the broader software engineering industry, web scraping is often defined as the automated gathering of information from the internet. In quantitative finance, we require a technical definition.
Web scraping is the automated, programmatic execution of HTTP network protocols to request, receive, and extract specific data structures from external servers, translating unstructured or semi-structured web payloads into strict, localized, memory-contiguous matrices for immediate algorithmic ingestion.
To know more about scraping check that pdf:
When a quantitative researcher builds a cross-sectional momentum strategy or a fundamental mean-reversion model, the model requires historical price vectors, dividend yields, expense ratios, constituent weights, etc. Historically, this data was locked behind expensive, proprietary data terminals operated by a few institutional vendors.
Web scraping bypasses this vendor lock-in. It allows a trading desk to aggregate fragmented public data from asset managers, regulatory filings, and financial portals directly into a local array or a structured SQL database. It is the direct acquisition of the raw material required for alpha generation.
Furthermore, standard vendor data is often commoditized. If every quant receives the exact same fundamental dataset at the exact same millisecond via an identical API feed, the alpha decays. Constructing custom extraction architecture allows a quantitative team to ingest alternative data—such as retail sentiment from localized forums, unstructured XBRL data from SEC 10-Q filings, or dynamically updating ETF composition lists directly from the issuer’s backend.

Where does it come from?
The methodology of data extraction has evolved in parallel with the evolution of web architecture itself. We can trace this lineage through distinct technological eras, driven by the need to parse complex data delivery mechanisms. Understanding this history is critical to understanding why modern quantitative infrastructure rejects certain parsing libraries.
Era 1: Static transfer and regular expressions
In the early days of the internet, web pages were static HTML documents stored directly on server hard drives. When a client sent an HTTP GET request, the server responded with the exact text file. Scraping in this era involved basic command-line tools executing standard network fetches.
The data was extracted using Regular Expressions (Regex). Regex operates as a finite state machine that matches specific string patterns. If a researcher wanted a stock price, they wrote a strictly defined string-matching algorithm to locate a sequence of numbers immediately following a specific HTML text block.
This was efficient computationally. A regex search over a 10-megabyte text file resolves in milliseconds. However, it was incredibly brittle from an operational standpoint. Consider the following HTML string: <td class="price">150.25</td>. A regex designed to capture the float inside the tags (r'class="price">(\d+\.\d+)<') works fine. But if the webmaster updates the website and injects a bold tag for visual styling—<td class="price"><b>150.25</b></td>—the regex logic fails. It returns a null value. In a trading pipeline, a null value propagates through the covariance matrix, zeroes out the optimization weights, and halts the entire trading execution.
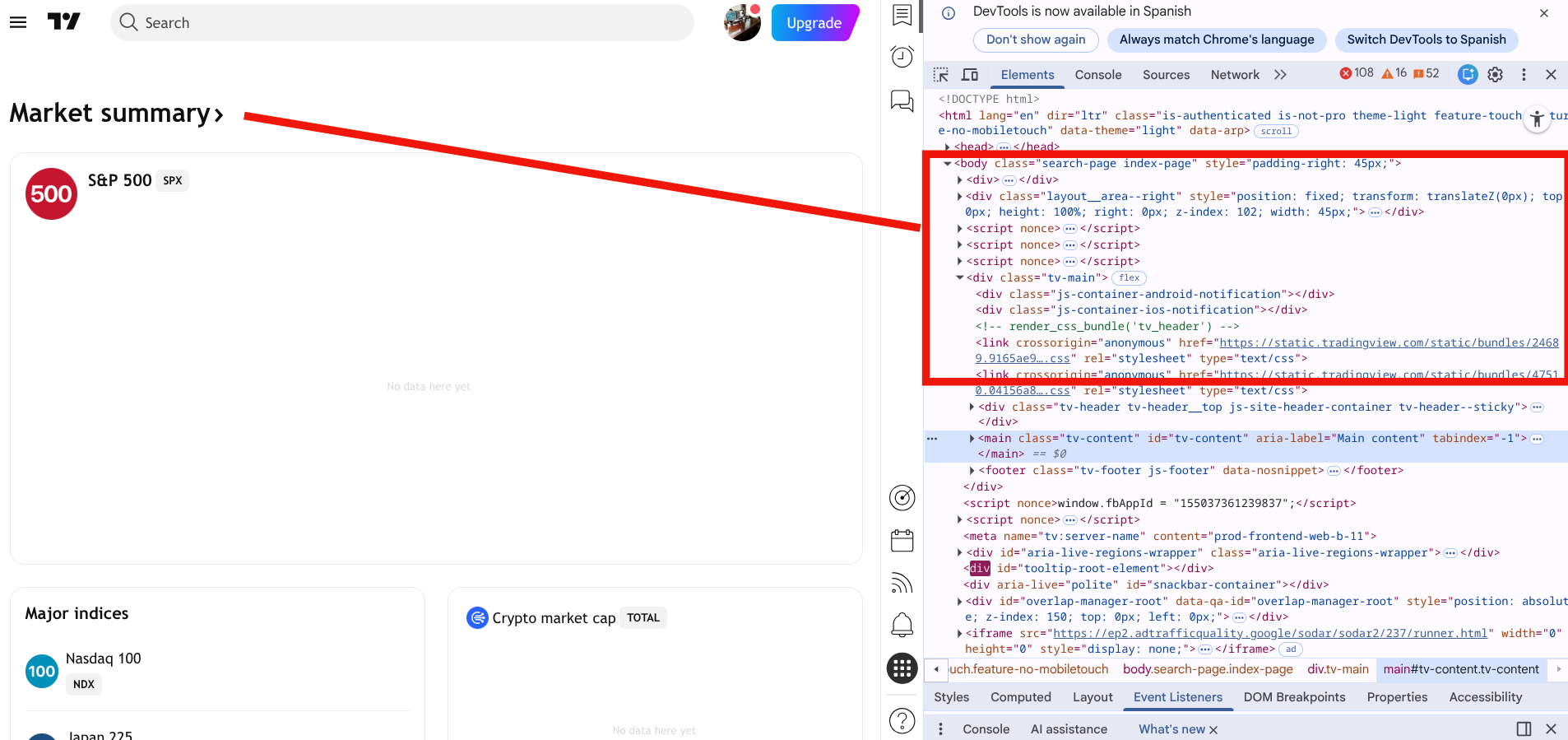
Era 2: The Document Object Model and structural parsing
As web pages evolved into generated templates mapping to backend databases, relying on raw string matching became impossible. The industry shifted to structural parsing. Browsers render HTML into a hierarchical tree structure known as the Document Object Model (DOM).
Scrapers evolved to replicate this exact rendering process in memory. Python libraries, such as BeautifulSoup utilizing lxml parsers, were developed to download the HTML string, parse it into an internal tree data structure, and allow engineers to search the tree using XPath or CSS selectors. We stopped searching for text strings and started searching for specific structural nodes, such as the third cell of the second row within a specific table ID.
While more robust than Regex, structural parsing introduces severe computational overhead. Converting a 5-megabyte HTML string into a fully traversable DOM tree requires significant CPU cycles and RAM allocation. The search algorithm must execute O(N) traversal operations across thousands of nested nodes. When running high-frequency data ingestion across thousands of financial instruments, the CPU time spent building these DOM trees severely limits the concurrency capacity of the extraction server.
Era 3: Single Page Applications and JavaScript rendering
The critical inflection point occurred when web development shifted to reactive JavaScript frameworks (React, Angular, Vue). The server no longer returned HTML containing the financial data. Instead, the server returned an empty HTML shell and a massive JavaScript file. The client’s browser was expected to execute the JavaScript, which would then dynamically fetch the data and build the DOM locally on the user’s machine.
Standard HTML parsers broke; they would download the empty shell, parse it, and find zero data. To combat this, scrapers evolved into headless browsers. Infrastructure had to spin up entirely automated, invisible instances of Chromium in the background, load the page, wait for the V8 JavaScript engine to execute the rendering logic, wait for the network requests to resolve, and then extract the data from the rendered DOM.
This was disastrous. Running a single headless browser instance requires hundreds of megabytes of RAM. If a quantitative pipeline requires 100 concurrent workers to update the daily pricing matrix before the market opens, the server must allocate over 50 gigabytes of RAM strictly for browser overhead. This is inefficient and unscalable for certain types of trading systems.
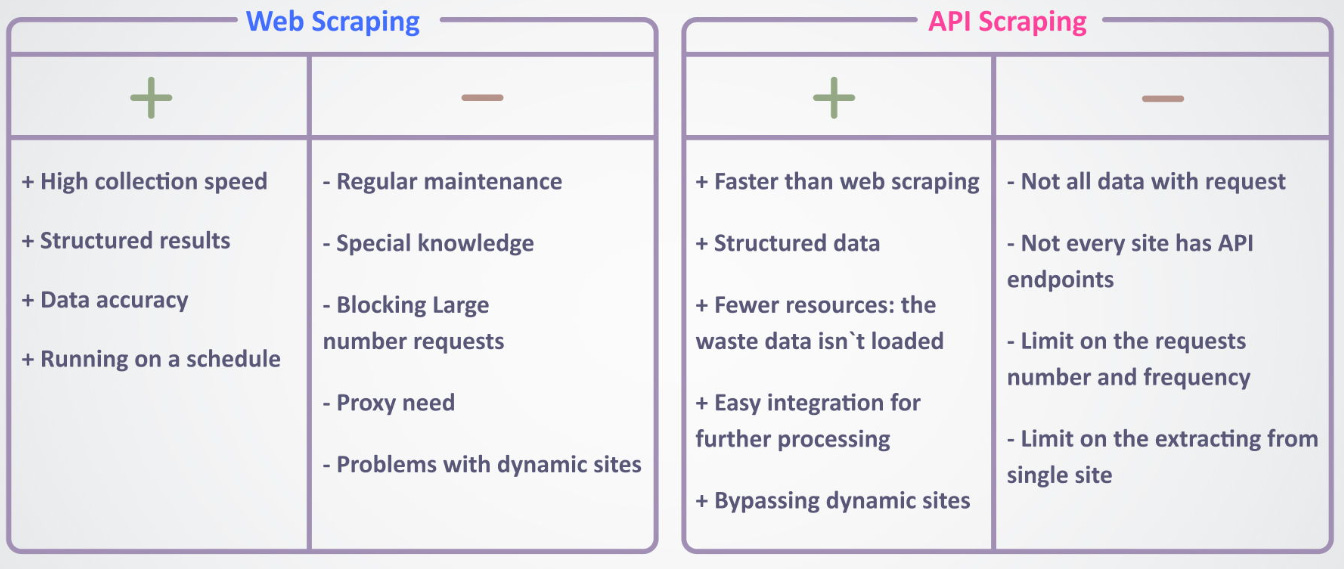
Era 4: API interception
This brings us to the modern quantitative standard. Because Single Page Applications must retrieve their dynamic data from somewhere, they utilize Application Programming Interfaces (APIs)—typically REST or GraphQL architectures.
Instead of rendering a heavy headless browser, we utilize network monitoring tools to observe the traffic generated by the web application. We identify the exact API endpoint the JavaScript is querying, and we replicate that precise HTTP request from our Python architecture. We bypass the HTML entirely. We bypass the JavaScript rendering engine. We request the raw, serialized JSON data directly from the provider’s backend database. This is the optimal state of data extraction: maximum fidelity, minimum computational overhead.
How web scraping actually works
To extract data, you must understand the exact sequence of network events that occur during a programmatic request. Web scraping is the programmatic automation of the standard client-server architecture, executing at speeds unachievable by human interaction.
Step 1: The network handshake and request formulation
The process begins when our Python architecture instantiates a TCP connection. We formulate a strict HTTP request, this request consists of a specific method (GET for retrieving data, POST for submitting query parameters), the target URL, and a dictionary of Headers.
Headers are critical, they dictate the exact rules of engagement with the target server. We set the User-Agent header to declare what type of client we are. By default, Python networking libraries broadcast their standard identity (e.g., python-requests/2.31.0). Modern Web Application Firewalls flag this string and drop the TCP connection. We must inject standard browser headers to bypass basic heuristic checks.
Furthermore, we must configure advanced headers such as Accept-Encoding: gzip, deflate, br to inform the server that we can handle compressed byte streams, reducing network transit time.
Modern security also involves TLS (Transport Layer Security) fingerprinting. Servers analyze the specific cryptographic cipher suites our client proposes during the initial connection setup (the Client Hello packet). Standard Python networking libraries propose a different sequence of ciphers than a standard Google Chrome browser. If the server detects a mismatch between the User-Agent claiming to be Chrome and a TLS fingerprint matching Python, it blocks the request. Advanced quantitative architecture utilizes specialized network adapters to mimic exact browser TLS signatures, guaranteeing connection acceptance.
Before we even introduce anything, let’s start here with our practical example.
import requests
url = "https://lt.morningstar.com/api/rest.svc/klr5zyak8x/security/screener?page=1&pageSize=50&sortOrder=ReturnM120%20desc&outputType=json&version=1&languageId=es-ES¤cyId=EUR&universeIds=FOESP%24%24ALL&securityDataPoints=SecId%7CName%7CPriceCurrency%7CTenforeId%7CLegalName%7CClosePrice%7CYield_M12%7CCategoryName%7CAnalystRatingScale%7CStarRatingM255%7CQuantitativeRating%7CSustainabilityRank%7CReturnD1%7CReturnW1%7CReturnM1%7CReturnM3%7CReturnM6%7CReturnM0%7CReturnM12%7CReturnM36%7CReturnM60%7CReturnM120%7CFeeLevel%7CManagerTenure%7CMaxDeferredLoad%7CInitialPurchase%7CFundTNAV%7CEquityStyleBox%7CBondStyleBox%7CAverageMarketCapital%7CAverageCreditQualityCode%7CEffectiveDuration%7CMorningstarRiskM255%7CAlphaM36%7CBetaM36%7CR2M36%7CStandardDeviationM36%7CSharpeM36%7CTrackRecordExtension&filters=&term=&subUniverseId="
r = requests.get(url, timeout=20)
print("status:", r.status_code)
print("content-type:", r.headers.get("content-type"))
print("content-encoding:", r.headers.get("content-encoding"))
print("head:", r.text[:200])Step 2: Server-side resolution and response
Upon receiving the formulated request, the target server evaluates it against its internal security protocols. It checks for IP reputation, rate limit thresholds (Token Bucket algorithms), and geographic blocking rules. If the request passes these validation checks, the server queries its internal SQL or NoSQL database, formats the result into the requested format, and transmits the payload back to our server over the open connection.
The server prefaces the payload with an HTTP Status Code. We evaluate this code before reading the data buffer. A 200 OK indicates absolute success. A 403 Forbidden indicates our IP or TLS signature was blocked by the WAF. A 429 Too Many Requests indicates we have exceeded the permissible concurrency limit. When a 429 is encountered, our infrastructure immediately halts execution on that specific thread and initiates a deterministic exponential backoff algorithm, calculating a precise wait time before re-attempting the connection.
status: 200
content-type: application/json
content-encoding: gzip
head: {"total": 49441,"page": 1,"pageSize": 50,"rows": [{"SecId": "F00000S8RT","Name": "Multipartner Konwave Gold Equity C USD","PriceCurrency": "USD","TenforeId": "52.8.LU1001014080","LegalName": "MultiparStep 3: Payload deserialization and matrix mapping
Once the payload bytes are received locally via the network interface card, they must be transformed into operational data. In modern scraping (API interception), the response header Content-Type is typically application/json. The data arrives as a serialized, UTF-8 encoded byte string.
We execute a high-speed deserialization function. In environments prioritizing microseconds, standard libraries are replaced by C-compiled alternatives like orjson or ujson that map JSON strings to memory structures faster. The deserializer parses the string and maps the key-value pairs into native Python dictionaries and lists.
From this state, we execute our extraction logic. We iterate through the arrays, filtering out the specific financial metrics we require, and allocating them into contiguous memory blocks. We actively cast data types at this stage—ensuring strings representing numbers are cast directly to float64 objects in a structured array, preparing the data for immediate ingestion into linear algebra operations.
To demonstrate the evolutionary mechanics, observe the explicit difference in code execution between legacy DOM parsing and modern high-speed JSON deserialization:
import json
from bs4 import BeautifulSoup
import orjson
import numpy as np
# Legacy Mechanics: Structural DOM Parsing (Era 2)
# The server returns a heavy string of markup logic mixed with data.
html_payload = """
<div class="financial-table">
<div class="row">
<span class="ticker">AAPL</span>
<span class="price">150.25</span>
</div>
</div>
"""
# We must allocate significant memory to build the entire tree structure just to find one float.
# This requires CPU cycles to parse the entire string, handle malformed tags, and build node relationships.
tree = BeautifulSoup(html_payload, "html.parser")
legacy_price = float(tree.find("span", class_="price").text)
# Modern Mechanics: API Deserialization (Era 4)
# The server returns strictly serialized data with zero HTML rendering logic.
json_payload_bytes = b'{"data": [{"ticker": "AAPL", "price": 150.25}]}'
# We execute a direct memory mapping using a C-optimized parser (orjson).
# This bypasses standard Python object creation overhead where possible.
parsed_data = orjson.loads(json_payload_bytes)
# We extract the specific float and immediately allocate it into a NumPy array type.
modern_price = np.float64(parsed_data["data"][0]["price"])The difference is structural and computational. Legacy scraping reads documents; modern scraping queries databases. By understanding the lineage and the strict network mechanics, we engineer scraping pipelines that don’t simulate human browsing. Instead, they operate as direct, high-speed, database-to-database communication protocols executing over the public internet.
Risks and limitations of the protocol
The execution of thousands of sequential HTTP requests introduces specific, quantifiable, and systemic risks to the trading infrastructure. These risks are guaranteed events in any large-scale network operation. They manifest as missing data rows, unhandled exceptions, TCP timeouts, and truncated JSON payloads, which directly corrupt the backtesting matrix.
The primary operational risks are categorized by standard HTTP response codes. We anticipate HTTP 429 (Too Many Requests) errors when our extraction loops exceed the provider’s token bucket algorithm limits. We expect TCP connection timeouts when network routing degrades. We will encounter 502 Bad Gateway responses during dynamic load balancer reallocations, and 503 Service Unavailable responses when the backend database cluster is executing routine locking operations or snapshots.
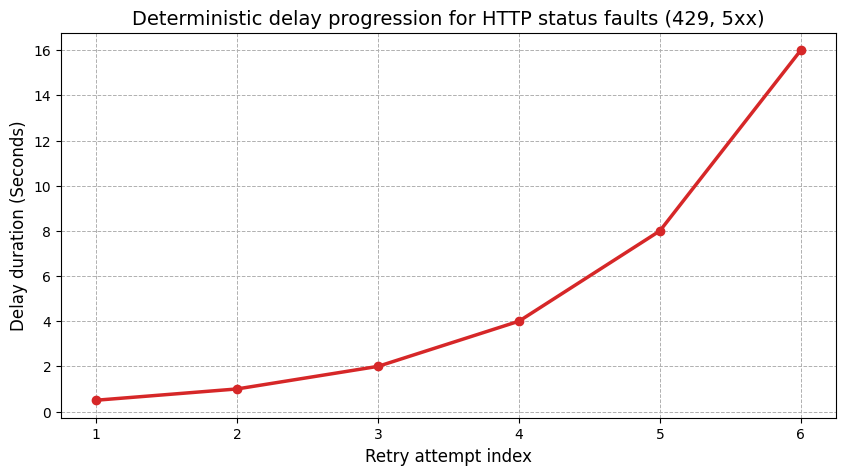
To mitigate these risks, we construct a session adapter using the urllib3 library. We implement a deterministic exponential backoff algorithm. When a 429 or 5xx status code is returned, the system pauses before executing a retry, reducing the concurrency pressure on the provider’s server. We target the 429, 500, 502, 503, and 504 codes. We exclude 400 (Bad Request) and 404 (Not Found) codes, as those represent structural errors in our query parameters that a retry will never resolve.
Here is the implementation of the retry adapter used in our pipeline:
import time
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
def _make_retry_adapter() -> HTTPAdapter:
retry = Retry(
total=6,
backoff_factor=0.5,
status_forcelist=(429, 500, 502, 503, 504),
allowed_methods=("GET",),
raise_on_status=False,
)
return HTTPAdapter(max_retries=retry, pool_connections=50, pool_maxsize=50)
def _lt_session() -> requests.Session:
# We precisely replicate standard browser headers to bypass basic WAF heuristic checks.
LT_HEADERS = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122 Safari/537.36",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "es-ES,es;q=0.9,en;q=0.8",
"Referer": "[https://lt.morningstar.com/](https://lt.morningstar.com/)",
}
s = requests.Session()
s.headers.update(LT_HEADERS)
adapter = _make_retry_adapter()
s.mount("https://", adapter)
s.mount("http://", adapter)
return s
Notice the specific performance parameters initialized in the adapter: pool_connections=50 and pool_maxsize=50. This keeps 50 distinct TCP connections open in the background, bound to the Session object. By utilizing the HTTP Keep-Alive header within the requests.Session architecture, we completely bypass the severe latency introduced by repeated Transport Layer Security handshakes.
Every new HTTPS request requires DNS resolution, a 3-way TCP handshake (SYN, SYN-ACK, ACK), and an expensive TLS cryptographic key exchange. This sequence requires 150 to 300 milliseconds of network overhead before a single byte of actual data is transmitted. This is the protocol tax. If we initiate a new session for 5,000 distinct requests, we incur 25 minutes of pure dead time negotiating connections. By pooling connections and persisting them, we reduce network overhead to the strict physical transfer time of the payload itself, dropping the marginal connection time to zero.
To visualize the progression of the exponential backoff risk mitigation, consider the following plot. It models the exact delay duration sequence based on the specified backoff_factor, demonstrating how the system slows down to prevent triggering a permanent IP ban.
This is the precise moment the entire architecture upgrades. We stop looking at the rendered web page, and we start interrogating the network layer.
By opening the developer tools within a controlled Chromium environment and monitoring the Fetch/XHR network traffic generated by the web application during standard user interaction, we discover and intercept the underlying API. We isolate the exact network request executing the database search. We identify the explicit endpoint serving the raw data to the frontend UI:
https://lt.morningstar.com/api/rest.svc/klr5zyak8x/security/screener.This endpoint doesn’t return complex, nested HTML documents. It accepts defined query parameters that dictate the SQL-equivalent operations on the backend: pagination offsets, sorting directives, universe limiters, and projection columns (securityDataPoints). In return, it provides a raw JSON payload.
By interfacing with this REST API, the extraction process transitions from a heuristic, error-prone text-parsing operation into a deterministic database query. We send a formalized HTTP GET request, and we receive a serialized data structure that maps into our operational memory. A float value is transmitted as a float. A string is transmitted as a string. There is no string-manipulation required to strip percentage signs or currency symbols, which eliminates an entire class of data engineering bugs.
This single event renders all traditional web scraping techniques—BeautifulSoup HTML parsing, XPath selection, and resource-heavy headless browsers like Selenium or Playwright— obsolete within our infrastructure.
Screener network topography
Having established the foundational infrastructure and intercepted the correct REST API endpoint, we now face the challenge of extracting the financial data. The provider’s backend database contains tens of thousands of mutual funds, exchange-traded funds, and institutional share classes. This dataset is vastly larger than the maximum permitted payload size for a single HTTP response.
The endpoint enforces a strict pageSize limit. This is a direct mechanism to prevent memory exhaustion on their internal database cluster. When a client requests data, the provider’s server must execute a SQL or NoSQL query, allocate a continuous block of RAM to hold the result set, serialize that data into a JSON string, and transmit it over the network interface. Requesting 10,000 rows creates a massive serialization overhead. To bypass these hard limits, we define our extraction parameter as pageSize=50.
Extracting the complete cross-sectional universe requires mapping the network topography and iterating over a paginated endpoint recursively. We must calculate the required number of requests based on the total record count returned in the initial response. We can’t hardcode the total page count, as the universe size fluctuates daily due to fund liquidations, mergers, and new product launches.
The algorithmic execution proceeds sequentially for the initialization phase. We fetch page 1. We parse the initial JSON payload to read the total integer field, which dictates the absolute size of the dataset for that specific query. We calculate the ceiling of the division of total by pageSize (math.ceil(total / page_size)). This yields the exact integer value of total pages required to complete the extraction. If the total is 0, we default to 1 to avoid ZeroDivisionError exceptions in downstream processing logic.
Besides, we pass specific query parameters in the HTTP request: universeIds=FOESP$$ALL specifies the precise fund universe routing key on the provider’s backend. We inject the parameter securityDataPoints=SecId|LegalName|CategoryName|ReturnM120 to isolate only the necessary relational columns.
We request the SecId, the LegalName, the CategoryName, and the ReturnM120 (the 120-month historical return, which is the foundational variable for long-term quantitative momentum analysis).
If we omit the securityDataPoints parameter, the API defaults to returning every available column—over 100 data points including tracking error, manager tenure, and daily standard deviation. This inflates the JSON payload from 50 kilobytes to over 5 megabytes per page. Requesting unnecessary data points saturates network bandwidth, increases TLS decryption time, and degrades the JSON parsing speed. We limit the payload to our exact algorithmic requirements.
import math
import numpy as np
import requests
LT_BASE = "[https://lt.morningstar.com/api/rest.svc/klr5zyak8x/security/screener](https://lt.morningstar.com/api/rest.svc/klr5zyak8x/security/screener)"
SECURITY_POINTS = "SecId|LegalName|CategoryName|ReturnM120"
def fetch_lt_page(session: requests.Session, page: int, page_size: int) -> dict:
params = {
"page": int(page),
"pageSize": int(page_size),
"sortOrder": "ReturnM120 desc",
"outputType": "json",
"version": 1,
"languageId": "es-ES",
"currencyId": "EUR",
"universeIds": "FOESP$$ALL",
"securityDataPoints": SECURITY_POINTS,
"filters": "",
"term": "",
"subUniverseId": "",
}
# Notice the exact tuple for the timeout: (4, 20)
# 4 seconds allocated for the TCP SYN/ACK connection handshake.
# 20 seconds allocated for the server to process the query and return the first byte.
r = session.get(LT_BASE, params=params, timeout=(4, 20))
ct = (r.headers.get("content-type") or "").lower()
if r.status_code != 200 or "json" not in ct or not r.content:
raise RuntimeError(f"LT bad response: {r.status_code} ct={ct} head={r.text[:200]!r}")
return r.json()
def _normalize_pages(pages, total_pages: int):
# This logic dictates the strict operational scope of the extraction matrix.
if pages is None:
# None implies a full universe extraction. WARNING: Huge data pull spanning gigabytes of memory.
return range(1, total_pages + 1)
if isinstance(pages, (int, np.integer)):
# Integer implies pulling the top N pages strictly based on the sortOrder parameter.
n = int(pages)
return range(1, min(max(n, 0), total_pages) + 1)
# List implies pulling specific, explicit page indices, useful for error-handling retry loops.
# We apply a set comprehension to mathematically eliminate duplicate page requests.
lst = sorted({int(p) for p in pages if 1 <= int(p) <= total_pages})
return lstThe pagination handler _normalize_pages is engineered to accept three distinct input states, providing the system with deterministic flexibility. If a researcher is running a lightweight daily update to assess the top decile of momentum performers, they pass an integer pages=10 to scan only the top 500 funds. If the infrastructure team is bootstrapping the initial quantitative database from a blank state, they pass None to fetch the absolute entirety of the universe. If a previous extraction loop dropped specific network packets, the error handler passes a list pages=[14, 22, 105] to specifically target the missing vectors. The use of a set comprehension {int(p) ...} guarantees that duplicate page indices are stripped before execution, preventing redundant network I/O.
We append these scalar values into localized lists. Python lists operate with O(1) amortized append time complexity because they over-allocate memory buffers under the hood. We can’t initialize the final, rigid structured array at this specific stage because we don’t yet know the exact valid row count; we filter out invalid JSON objects—such as funds missing a critical SecId—during the loop.
The primary obstacle at the screener stage is managing the sequential nature of the pagination discovery. Because we don’t possess the total integer until the very first request resolves and the JSON is parsed, the initial discovery phase is linear. However, once the total_pages parameter is acquired, the subsequent page requests become entirely stateless and independent. This sets the theoretical stage for future parallelization. Yet, for this specific screener layer, executing sequential HTTP requests over an established, persistent TLS connection pool is efficient, completing the initial metadata extraction in a matter of a few seconds, preparing the matrix for the much heavier, threaded Global API processing phase.

Scraping fund positions
The screener endpoint provides the fund-level metadata, consisting of basic identifying parameters and historical return vectors. However, a fund’s surface-level metadata is insufficient for risk management and alpha generation. To construct a look-through portfolio, assess true factor exposure, or run Barra risk decomposition models, we require the exact equity holdings inside each fund. We need the underlying constituents, and we need them weighted.
This data requirement introduces a separate, more complex endpoint into our architecture: the Global API (api-global.morningstar.com). Unlike the public screener interface, this endpoint demands an explicit authentication mechanism. We must inject an apikey (it’s free) header into every request.
# 2) Direct holdings
APIKEY = "HERE YOUR API KEY"Furthermore, the endpoint requires the specific SecId extracted from the first phase to be formatted directly into the URL path.
The primary architectural obstacle is the sheer volume of network requests. The screener API supports bulk pagination; the Global API doesn’t. If the screener returns an array of 5,000 distinct funds, we must execute 5,000 separate, individual HTTP GET requests to the Global API to retrieve the constituent holdings for each individual fund.
A standard, sequential execution loop operates at approximately 0.5 seconds per request. This delay is a function of the physical network latency—the round-trip time between our trading servers and the provider’s data center, plus the provider’s internal database query execution time. Executing 5,000 requests sequentially requires 2,500 seconds, equating to over 40 minutes of pure execution time. This is unacceptable for a daily production pipeline that must process data, run optimizations, and generate execution orders before the market open.
We resolve this processing bottleneck through concurrent execution. We implement a ThreadPoolExecutor from the concurrent.futures module. Because HTTP network requests are I/O-bound tasks—meaning the CPU sits idle while waiting for the network interface card to receive the inbound packet from the remote server—the GIL doesn’t inhibit parallel execution in this specific scenario. The interpreter releases the GIL during standard I/O blocking operations. Therefore, we can launch 20 concurrent threads to process the requests without migrating to a complex multiprocessing architecture.
We chose thread pooling over an asynchronous event loop (like asyncio) because our existing network infrastructure relies on the requests library and custom urllib3 retry adapters. Threaded execution provides the exact same I/O concurrency benefits without requiring a complete rewrite of the underlying synchronous network stack.
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
import numpy as np
APIKEY = "HERE YOUR API KEY"
MS_BASE = "[https://api-global.morningstar.com/sal-service/v1/fund/portfolio/holding/v2](https://api-global.morningstar.com/sal-service/v1/fund/portfolio/holding/v2)"
MS_HEADERS = {
"apikey": APIKEY,
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36",
"Accept": "application/json, text/plain, */*",
}
_thread_local = threading.local()
def _ms_session() -> requests.Session:
# We must ensure strict thread safety across concurrent network operations.
s = getattr(_thread_local, "session", None)
if s is None:
s = requests.Session()
s.headers.update(MS_HEADERS)
# Assuming _make_retry_adapter is defined as in Part 1 for exponential backoff
# s.mount("https://", _make_retry_adapter())
_thread_local.session = s
return s
def fetch_holdings_us_topN(secid: str, country: str = "United States", top: int = 10):
s = _ms_session()
url = f"{MS_BASE}/{secid}/data"
params = {
"clientId": "MDC",
"version": "4.71.0",
"premiumNum": 10000,
"freeNum": 10000,
}
r = s.get(url, params=params, timeout=(4, 25))
if r.status_code != 200 or not r.content:
return []
data = r.json()
page = (data.get("equityHoldingPage") or {})
hlist = (page.get("holdingList") or [])
out = []
for h in hlist:
c = h.get("country") or h.get("countryName")
if c == country:
t = h.get("ticker") or h.get("tradingSymbol")
if t:
out.append(t)
if len(out) >= top:
break
return out
def attach_holdings_all(secids, max_workers: int = 20, country: str = "United States", top: int = 10):
holdings = [None] * len(secids)
with ThreadPoolExecutor(max_workers=max_workers) as ex:
futs = {ex.submit(fetch_holdings_us_topN, sid, country, top): i for i, sid in enumerate(secids)}
for fut in as_completed(futs):
i = futs[fut]
try:
holdings[i] = fut.result()
except Exception:
# We enforce strict failure handling to maintain array dimensions.
holdings[i] = []
return np.asarray(holdings, dtype=object)Observe the use of threading.local(). This is an essential architectural detail that prevents systemic failure. We instantiate a unique requests.Session() object for every single active thread. When multiple concurrent connections interact with a single, shared urllib3 connection pool, race conditions occur at the socket level, leading to corrupted TCP streams and dropped connections. By isolating the session object to local thread memory storage, we guarantee that each thread maintains its own independent pool of Keep-Alive HTTP sockets. This ensures deterministic network execution.
We limit max_workers=20 as calculated threshold based on the provider’s implicit rate limits. Exceeding this thread count doesn’t yield linear performance gains; instead, it triggers the provider’s Web Application Firewall, which responds with HTTP 429 status codes, forcing our exponential backoff adapter into extended sleep cycles. Twenty workers provide the optimal equilibrium between maximum extraction speed and minimal server-side rejection.
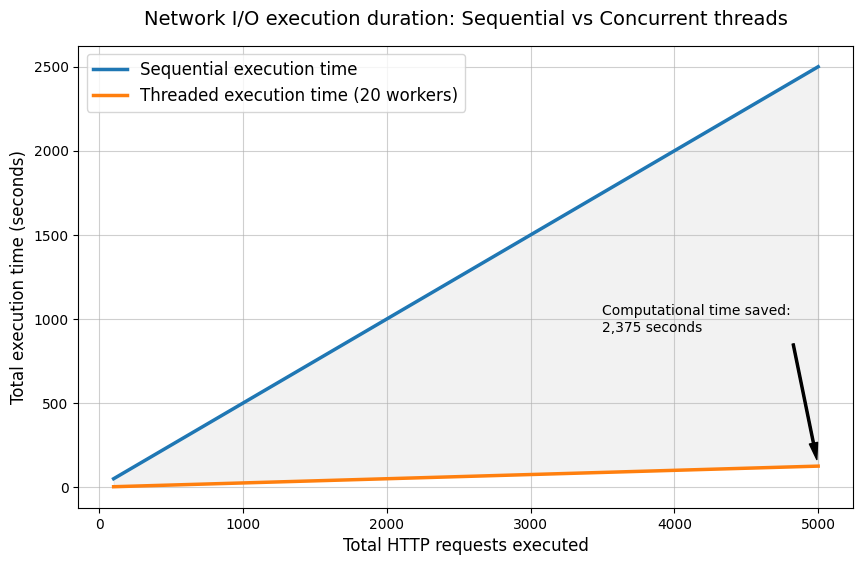
The next part is to map the extracted data into a NumPy structured array. A structured array allocates a single, contiguous block of memory in C. We define exact byte boundaries for each field in the matrix. When the CPU executes operations on this array, it loads sequential memory blocks directly into the L1/L2 cache, executing instructions with zero pointer-chasing overhead.
We allocate a 16-character unicode string (U16) for the SecId, a 256-character unicode string (U256) for the Fund name, an 8-byte float (f8) for the return metric, and an object pointer (O) for the variable-length list of constituent stock holdings.
# Execution assembly demonstrating the structured array initialization
import numpy as np
# Assuming secids, names, rets, and stocks are already populated lists/arrays from the extraction phase
# We allocate exactly the required memory footprint before population.
arr = np.empty(len(secids), dtype=[("Id", "U16"), ("Fund", "U256"), ("ReturnM120", "f8"), ("Stocks", "O")])
arr["Id"] = np.asarray(secids, dtype="U16")
arr["Fund"] = np.asarray(names, dtype="U256")
arr["ReturnM120"] = rets
arr["Stocks"] = stocksWe acknowledge the use of the object pointer ("O") for the stocks column breaks strict C-contiguity for the holding string arrays themselves. However, this is computationally acceptable because our heavy numerical operations—the sorting and ranking logic—operate on the f8 float array, which remains contiguous and hardware-optimized.
Furthermore, we must handle missing data points at the numerical level. Web scraped data contains holes; some funds lack a 10-year track record. We temporarily replace NaN values with negative infinity (-np.inf) prior to sorting. Standard sorting functions in C don’t possess financial logic. Mathematical comparisons against NaN fail silently (NaN > 5 evaluates to False, NaN < 5 evaluates to False). If we don’t execute this specific substitution, NaN values sort unpredictably, injecting null pointers into the highest momentum deciles and breaking the downstream portfolio construction models. This substitution ensures that funds lacking complete return histories are forced to the absolute bottom of the generated matrix.
def sort_by_return_desc(arr: np.ndarray) -> np.ndarray:
if arr.size == 0:
return arr
r = arr["ReturnM120"]
# Isolate NaN values and push them to the lowest possible finite float boundary (-inf).
# This prevents incomplete track records from ranking highly in momentum strategies.
r2 = np.where(np.isfinite(r), r, -np.inf)
# Execute the C-level sort on the substituted float array, and reverse it ([::-1]) for descending order.
idx = np.argsort(r2)[::-1]
# Return the newly aligned, completely contiguous memory view.
return arr[idx]
The final, most complex important barrier in systematic fund scraping is the share class multiplicity problem. Asset managers construct a single underlying portfolio of equities, but they distribute that identical portfolio across dozens of distinct administrative wrappers. They do this to target different regulatory jurisdictions, implement varying management fee structures, and separate retail investors from institutional capital. Consequently, you will see Institutional classes, Retail classes, Accumulating (Acc) classes, Distributing (Inc) classes, GBP hedged variants, and EUR unhedged variants—all holding the exact same underlying assets in the exact same proportions.
A standard database unique constraint operating on the SecId is insufficient here because each distinct share class possesses a unique Morningstar SecId. If we include all share classes in a model without aggressive deduplication, we introduce multicollinearity into the output.
We must reduce the dataset to a single representative vector per underlying portfolio. We achieve this by cross-referencing two distinct topographical vectors: the exact list signature of the underlying top holdings, and a strict lexical analysis of the fund’s string name.
First, we define a tokenization function to strip punctuation and structural noise from the fund name strings. We use regular expressions to explicitly remove parentheses and brackets, as share classes are frequently denoted by suffixes like “(USD)” or “[Acc]”. Stripping these allows us to isolate the core lexical identity of the fund. We then define an algorithmic function to calculate the strict length of the common prefix between two tokenized arrays.
def _name_tokens(name: str) -> list[str]:
s = (name or "").strip().lower()
# Normalize common typographic variations in fund prospectuses
s = s.replace("–", "-").replace("—", "-")
# Strip isolating punctuation typically used for share class designations
s = re.sub(r"[()\[\],]", " ", s)
return [t for t in s.split() if t]
def _common_prefix_len(a: list[str], b: list[str]) -> int:
n = min(len(a), len(b))
k = 0
# Calculate exact sequential token matches from index 0
while k < n and a[k] == b[k]:
k += 1
return k
The clustering logic dictates a two-factor rule: two rows are identified as overlapping if and only if their top 10 holding tickers match exactly (creating a deterministic tuple signature) AND their fund names share a strong lexical prefix.
Why both? Relying solely on the holdings signature is dangerous. Two different passive index funds managed by different firms might hold the exact same top 10 mega-cap technology stocks. If we only checked holdings, we would collapse two distinct operational funds into one.
By enforcing the lexical prefix check, we ensure accuracy. If ‘Global Equity Fund Class A USD’ and ‘Global Equity Fund Class B EUR’ possess the exact same stocks, their holding tuple signature matches. Their tokenized prefix ['global', 'equity', 'fund'] also matches based on our defined threshold (e.g., 60% of the token length). Therefore, they are safely clustered together as a single entity.
Once clustered, we invoke a selection algorithm. We iterate over the array indices within the cluster, evaluate the ReturnM120 float vector, and retain the exact index containing the maximum finite return value.
We select for the maximum 120-month return because older, institutional share classes exhibit longer, uninterrupted historical track records and lower fee drags than newer retail classes. Retaining the asset with the longest valid track record is optimal for backtesting; it maximizes our sample size and statistical significance across different historical market regimes.
def _pick_best_index(arr: np.ndarray, idxs: list[int], keep: str = "max_return") -> int:
if keep == "first":
return idxs[0]
best = idxs[0]
best_r = arr["ReturnM120"][best]
for i in idxs[1:]:
r = arr["ReturnM120"][i]
r_ok = np.isfinite(r)
b_ok = np.isfinite(best_r)
# We strictly prioritize finite, measurable returns over NaN or infinite values.
# If the current best is NaN, any finite return replaces it immediately.
if (r_ok and not b_ok) or (r_ok and b_ok and r > best_r):
best = i
best_r = r
return best
def dedupe_unnecessary_share_classes(arr: np.ndarray, min_prefix_tokens=8, prefix_ratio=0.60, keep="max_return") -> np.ndarray:
if arr.size == 0:
return arr
groups: dict[tuple, list[int]] = {}
unique_empty_keys: list[int] = []
tokens_cache = [None] * arr.size
for i in range(arr.size):
tokens_cache[i] = _name_tokens(str(arr["Fund"][i]))
stocks = arr["Stocks"][i]
try:
# Convert the list of tickers into an immutable, hashable tuple for O(1) dictionary lookups
sig = tuple(stocks) if stocks else tuple()
except TypeError:
sig = tuple()
if len(sig) == 0:
unique_empty_keys.append(i)
else:
groups.setdefault(sig, []).append(i)
kept = set(unique_empty_keys)
for sig, idxs in groups.items():
# Sort by name to guarantee deterministic execution across multiple pipeline runs
idxs_sorted = sorted(idxs, key=lambda i: arr["Fund"][i])
clusters: list[list[int]] = []
reps: list[int] = []
for i in idxs_sorted:
ti = tokens_cache[i]
placed = False
for c_idx, rep_i in enumerate(reps):
tr = tokens_cache[rep_i]
cpl = _common_prefix_len(ti, tr)
# Dynamic threshold calculation ensures short names and long names are evaluated fairly
threshold = max(min_prefix_tokens, int(math.ceil(prefix_ratio * min(len(ti), len(tr)))))
if cpl >= threshold:
clusters[c_idx].append(i)
placed = True
break
if not placed:
reps.append(i)
clusters.append([i])
for cl in clusters:
kept.add(_pick_best_index(arr, cl, keep=keep))
kept_idx = np.array(sorted(kept), dtype=int)
return arr[kept_idx]So let’s see what we got from this. Time to test!
Oh! This looks good to me!
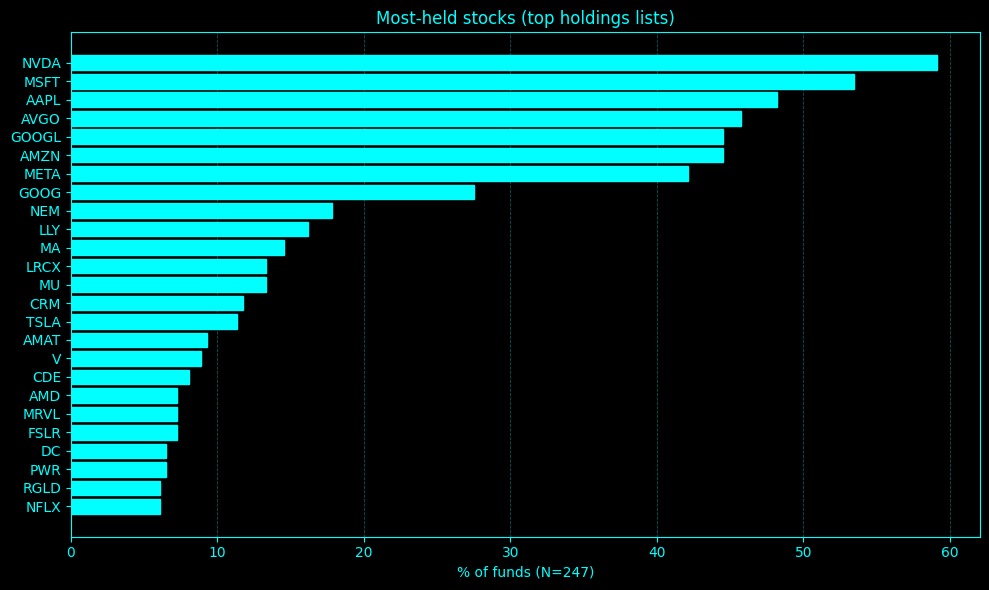
Screener Extract: 498 funds in 11.567s | Holdings Intercept: 7.711s | Total Architecture Execution: 19.278s | Matrix Dedupe Reduction: 498 -> 346 strict portfolios
[('F00000S8RT', 'Multipartner SICAV - Konwave Gold Equity Fund C USD', 25.92, list(['AU']))
('0P0000OMTB', 'Polar Capital Funds PLC - Polar Capital Global Technology Fund I Income EUR', 25.56, list(['NVDA', 'AVGO', 'AMD', 'META', 'LRCX', 'KLAC', 'LITE', 'COHR', 'SNDK', 'STX']))
('F0GBR04H0X', 'Multipartner SICAV - Konwave Gold Equity Fund B USD', 25.38, list(['AU']))
('F00000VI1X', 'Bakersteel Global Funds SICAV - Precious Metals Fund D EUR', 24.62, list(['NEM', 'AU', 'CDE']))
('F00001S8MC', 'CT (Lux) - Global Technology Class ZE (EUR Accumulation Shares)', 23.5 , list(['BE', 'LRCX', 'NVDA', 'AVGO', 'WDC', 'GOOGL', 'AMAT', 'MSFT', 'MRVL', 'AAPL']))]
Ticker Count PctFunds
--------------------------
NVDA 146 59.11
MSFT 132 53.44
AAPL 119 48.18
AVGO 113 45.75
GOOGL 110 44.53
AMZN 110 44.53
META 104 42.11
GOOG 68 27.53
NEM 44 17.81
LLY 40 16.19
MA 36 14.57
LRCX 33 13.36
MU 33 13.36
CRM 29 11.74
TSLA 28 11.34
AMAT 23 9.31
V 22 8.91
CDE 20 8.10
AMD 18 7.29
MRVL 18 7.29
FSLR 18 7.29
DC 16 6.48
PWR 16 6.48
RGLD 15 6.07
NFLX 15 6.07
Okay! No surprises here! This output matrix is formatted, computationally lightweight, and ready to be serialized to a Parquet file or whatelse. The architecture is resolved and ready for daily production scheduling.
Alright crew—good session today. Until the next article! And remember, may liquidity is with you! 💵
This is an invitation-only access to our QUANT COMMUNITY, so we verify numbers to avoid spammers and scammers. Feel free to join or decline at any time. Tap the WhatsApp icon below to join

Appendix
Full script: