


Table of contents:
Introduction.
What is feature selection?
Risks and limitations of feature selection.
Feature selection as a research problem.
Filter-based feature selection.
Information Gain.
Chi-Square test (X2).
Fisher score.
ANOVA F-Test.
Correlation with target.
ReliefF.
Minimum Redundancy Maximum Relevance.
Audio Note: Before we begin, remember that if you’re accessing this article through the Substack app, you can listen to it instead of reading it.

Before you begin, remember that you have an index with the newsletter content organized by clicking on the image below.

Introduction
Financial markets produce mountains of data, spanning simple price movements to limit order book dynamics. A common misconception assumes a larger dataset guarantees superior predictions. Reality proves the opposite. Excessive variables introduce noise, and invite to overfitting.
Every input added to a model represents a specific market hypothesis. Including a volatility metric implies price instability shapes future returns. Adding a spread feature connects liquidity to transaction costs. The selection process goes further than basic data preprocessing to become the core architectural decision of a trading system. The target variable dictates the necessary inputs, and aligning these inputs with actual market execution determines strategy success.
High-dimensional environments carry distinct dangers, exposing models to feature leakage, dimensional overreach, and selection instability. A feature might improve a statistical score in a backtest but erode capital in live trading due to increased turnover or delayed entries.
Go deeper in this topic by checking this presentation:

Let’s outline the mechanics and limitations of distinct statistical filters, including Information Gain, Chi-Square tests, Fisher Scores, ANOVA, and Mutual Information. Each method offers a unique lens for evaluating data, from measuring entropy reduction to capturing non-linear dependencies.
What is feature selection?
Feature selection is the process of deciding which variables deserve to enter a model and which variables should stay outside it. For example:
A return feature embeds the claim that recent price movement contains information about future outcomes.
A volatility feature treats the magnitude and instability of price movement as relevant to the future distribution of returns.
A volume feature assumes that participation carries informational value.
A spread feature connects liquidity conditions to execution quality, transaction costs, and the practical usefulness of a signal.
A regime feature formalizes the idea that market behavior changes across states.
Therefore, feature selection gives structure to the model. It separates useful information from noise, redundancy, leakage, and unnecessary complexity. A model can receive hundreds of possible inputs, while only a smaller group contributes to consistent performance. Its purpose is to reduce the model’s information set to the variables that improve prediction, reduce instability, and improve the final performance.

The point here is to know which variables remain useful when the model trades under live conditions. A selected feature must contribute beyond other similar variables and survive different market periods. Let us start with the feature set X = {x1, x2, …, xp}.
The problem can be stated simply. The original dataset contains (p) candidate features, each one representing a possible source of information for the model. Feature selection looks for a smaller subset S ⊂ X.
The objective is to choose (S) so the model performs better, generalizes better, and remains easier to monitor. In fact, performance must be measured through the full chain:
Then, a feature becomes valuable when it improves that chain. Conversely, a feature loses value when it improves a statistical score while weakening the final PnL. For example, a feature may improve directional accuracy from 51 percent to 52 percent. At first, that looks useful. Yet if the feature doubles turnover, increases transaction costs, and creates late entries, the strategy becomes weaker. Another feature may show only moderate predictive power, but it may reduce false entries during high-volatility periods. That feature becomes more valuable because it improves the strategy where losses usually appear.
This is why feature selection in follows a higher standard than ordinary data science. In many machine learning problems, the main question is predictive accuracy (that includes recall and F1). But in trading, the question is broader. The model needs useful predictions, stable signals, controlled turnover, and realistic execution across time.
Feature selection also protects the model from redundancy. Many variables express the same idea in different forms. A 5-day return, a 10-day momentum score, a moving-average slope, and a breakout distance may all describe directional pressure. Adding all of them can make the dataset look richer, while the model receives repeated exposure to the same underlying signal.
There are several common ways to select features. Low-variance filters remove variables that barely change. Univariate methods rank each feature by its individual relationship with the target. Recursive feature elimination repeatedly removes weaker variables from a model. L1 regularization pushes weak coefficients toward zero. Tree-based methods estimate which variables help nonlinear decisions. Sequential feature selection adds or removes variables based on their contribution to validation performance.
Feature selection is therefore both a modeling technique and a research control mechanism.

Risks and limitations of feature selection
As stated earlier, a broader feature set gives a model a richer pool for describing market structure. It expands the number of ways in which the model can represent volatility, direction, liquidity, regime behavior, cross-asset transmission, and conditional response. However, every additional feature gives the model another opportunity to attach meaning to patterns that may belong only to the accidental geometry of the sample.
Each feature therefore carries a hypothesis, and a failure mode. Let’s see these costs:
The first risk is dimensional overreach. A model with too many variables can produce excellent in-sample performance while increasing out-of-sample overfitting. This risk grows when the research process tests many transformations of the same underlying idea. A dataset may contain RSI 7, RSI 14, RSI 21, stochastic oscillators, z-scored returns, rolling quantiles, rolling ranks, and several normalized momentum measures. On the research dataframe, this appears diversified. But in market terms, it may express the same directional claim several times under different names.
This is one of the central traps of high-dimensional research. The number of variables grows faster than the number of independent market states. As the feature space expands, the probability of discovering a convincing but empty relationship increases.
The second risk is feature leakage. Leakage appears when a feature contains information that was unavailable at the moment of decision. This problem often appears in subtle forms. For example, a rolling statistic may include the current bar close while the simulated trade is placed at the open; or a volatility estimate may rely on high and low values that occur only after the entry decision.
Feature selection magnifies this problem because selection methods reward the variables that appear most predictive. It improves the validation score, stabilizes the equity curve, and gives the model an artificial sense of intelligence. The problem is that this intelligence is simply overfitting.
The third risk is selection instability. A feature can rank highly in one period, lose relevance in another, and return later. This behavior reflects regime dependence, sample noise, and structural decay. In fact, it sits close to the boundary between usefulness and randomness.
A feature that wins inside a backtest could lose practical value during live conditions. The apparent ranking of features can shift when the research process moves from statistical prediction to executable trading. A variable that improves a model score may still damage the strategy when placed inside the full execution chain.
The fourth risk is economic irrelevance. A feature can improve a statistical metric while weakening the actual trading system. It can raise accuracy from 51.0 percent to 51.5 percent and still reduce profitability when it increases turnover, or concentrates trades. In trading, every feature must be evaluated through its final contribution to the PnL because predictive usefulness alone is insufficient.
Feature selection is designed to reduce the model to useful information, yet the act of selecting features can itself become a source of bleeding money. The researcher uses feature selection to control complexity, but the selection process also needs its own control mechanism. Therefore, it requires more than ranking variables by historical usefulness. The feature set must remain coherent across time, robust under small perturbations, and aligned with the strategy’s market hypothesis.

Feature selection as a research problem
Feature selection can appear mechanical when it is presented as a catalogue of techniques. It creates the impression that a researcher can pass a dataset through a set of filters and obtain, at the end of the process, a smaller and more useful information set.
This impression is attractive because it transforms a difficult research decision into an apparently technical routine. However, the problem is a little bit more complex than that. Feature selection is a research problem because every feature represents a claim about future market behavior.
A lagged return claims that recent price movement contains useful information, while a volatility estimate claims that the current distribution of movement changes the next decision. There are tons of assumptions related to that, like those related to liquidity, cross-asset variable, regime variable and so on.
Selecting a feature therefore means selecting a market hypothesis.
This changes the role of feature selection completely. The researcher is reducing the number of columns in a dataset and deciding what the model is allowed to observe. That choice defines the structure of the model before the model begins to learn. A feature set with many versions of the same idea gives the model a narrow view expressed through many columns.
The first major challenge is temporal order. Trading data arrives through time. The researcher stands at time t, observes only the information available at time t, makes a decision for time t+1 or later, and receives the result only after the market has moved and after trading costs have entered the calculation. This structure changes the entire selection problem.
A feature used at time t must belong to the information set available at time t. The structure can be written as:
The position then follows from the selected information:
The future outcome appears only after the decision:
where qt is the position, rt,t+h is the future return over the holding horizon, and Ct represents commissions, spread, slippage, latency, etc. This small structure captures the essence of the trading problem. The model receives information, takes exposure, and earns a net result. Feature selection must improve that entire chain. This is why time alignment becomes central. The method may look correct while the experiment becomes false. The correctness lives in the timing of information.
The second major challenge comes from the target. In many ordinary prediction problems, the target has a direct definition. In trading, the target is a design decision: next-bar return, next-day return, probability of a positive close, volatility-adjusted return, maximum favorable excursion, maximum adverse excursion, triple-barrier outcome, trend continuation, mean-reversion response, drawdown-conditioned payoff, or expected return after costs. And a pretty long list where each target asks the features a different question.
For this reason, feature selection has to start with the trading objective, not with the dataset. Predicting next-day direction requires one type of information. Sizing exposure from volatility-adjusted expected return requires another. Trend continuation depends on evidence of persistence, while mean reversion depends on evidence of displacement and exhaustion. The same column can carry alpha in one objective and become almost useless in another.
For example, realized volatility may rank highly when the target is absolute return yt=|rt+1|. The same feature may rank much lower when the target is signed return yt=rt+1
Feature correlation is also a major challenge. Different selection methods react to correlation in different ways. This creates a practical problem because the selected feature list can change across time even when the underlying market idea remains stable. One month the model selects a five-day return and another month it selects a moving-average slope. The names change, while the concept remains close to the same directional signal. A shallow reading calls the model unstable. But it is just feature-level instability—from concept-level stability.
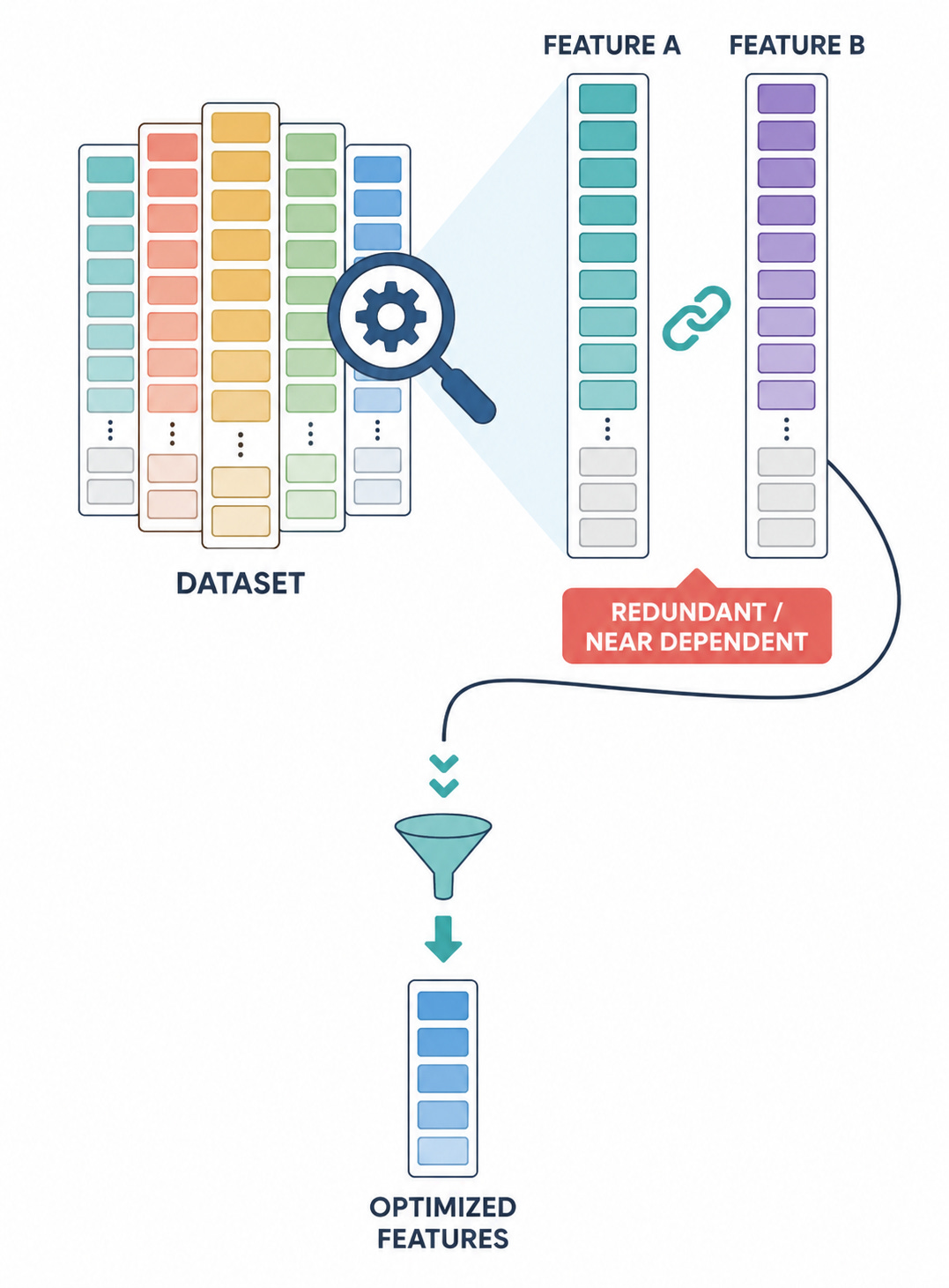
Due to all of that financial datasets can look large while containing limited independent information. Intraday data may contain millions of rows, yet many of those rows repeat the same session structure. Daily data may cover decades, yet it still contains a limited number of cycles, liquidity contractions, and structural breaks. The number of rows can exaggerate the amount of independent evidence.
The researcher therefore needs two forms of data sufficiency:
The first is observation count. The feature has to appear often enough for its relationship with the target to be estimated.
The second is regime coverage. The feature has to experience enough different market states for its survival to be tested.
A feature that performs across calm sessions, volatile sessions, gap sessions, trend days, reversal days… carries stronger evidence than a feature that performs in one narrow environment.
Feature selection does not work in isolation. Its value depends on the model that reads the features and the trading objective they are meant to serve. Each method reveals a different part of the picture, and the decision becomes stronger when those signals are interpreted together rather than treated as separate answers.
A prediction eventually has to become an order. That transition changes the evaluation because a feature can improve a prediction metric while weakening the final strategy. For this reason, feature selection must be judged by its effect on realized trading outcomes.

Filter-based feature selection
The curse of dimensionality presents a constant threat to model generalization. When designing trading models, researchers typically construct hundreds or thousands of candidate features from raw limit order book data, transaction flows, technical indicators, and macroeconomic series. Including redundant or uninformative variables accelerate overfitting, and degrades out-of-sample performance.
This is compounded by the low signal-to-noise ratio characteristic of financial markets, where genuine predictive signals are often buried under overwhelming market noise. If a model with high capacity (such as a deep neural network or a gradient-boosted tree) is fed an excessive number of noisy features, it will exploit spurious in-sample correlations, leading to capital loss during live deployment.
Filter-based methods are computationally efficient and model-agnostic. They evaluate the intrinsic statistical properties of individual candidate features relative to a target label—independent of the downstream training phase. This decoupling prevents the leakage of model-specific assumptions and acts as the first line of defense against data-snooping biases.