


Table of contents:
Introduction.
Risks and transformation limitations.
Processing text and features related to text.
Lexical canonicalization as a trading signal operator.
Token boundary specification and market microstructure semantics.
Stopword removal, negation retention, and signal integrity.
Lemmatization, stemming, and contextual LLM preprocessing.
Sparse and dense feature construction for event-driven alpha.
Alignment, and log-template parsing.
Before you begin, remember that you have an index with the newsletter content organized by clicking on the image below.

Introduction
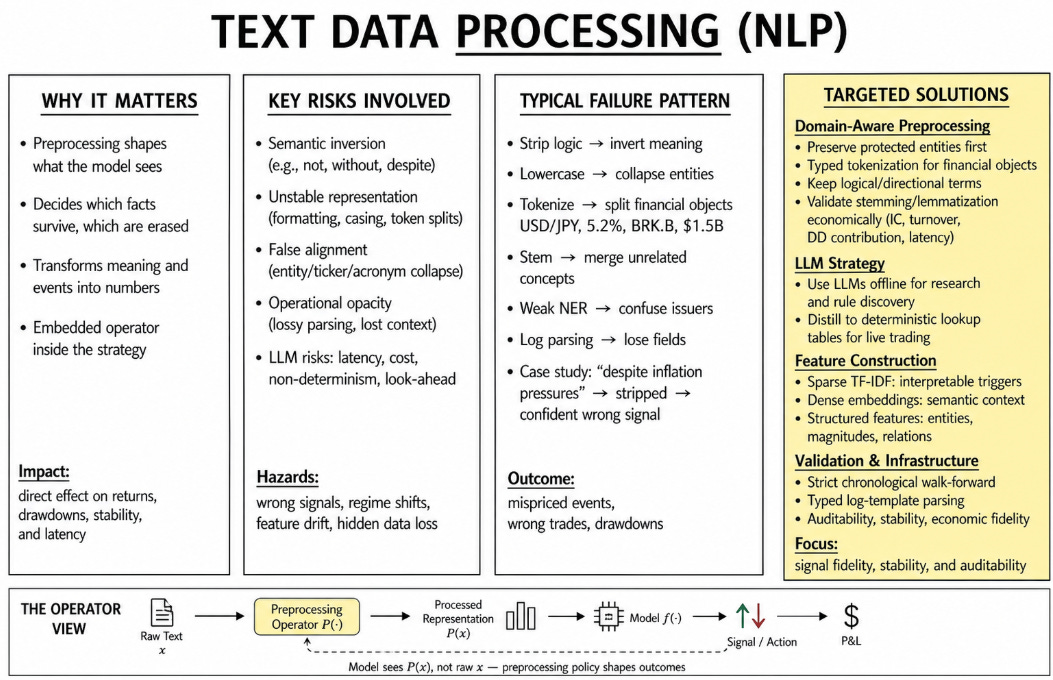
Between a market event and a model-generated trading signal exists a sequence of transformations that determines what the model is permitted to observe. Standard literature describes this sequence as text preprocessing. Tokenization partitions a character stream into discrete units. Normalization maps heterogeneous strings into canonical forms. Stopword removal deletes tokens according to frequency-based exclusion lists. Stemming and lemmatization compress morphological variants into common representations. Multiword grouping binds adjacent tokens into higher-order semantic objects. In conventional natural language processing, these operations are often treated as preliminary cleaning procedures. In algorithmic trading, they are active signal-shaping mechanisms.
Trading model receives the version of language produced by the preprocessing layer. A headline, filing paragraph, policy statement, earnings transcript, or execution log become usable information only after a pipeline decides which words survive, which strings are merged, which entities are protected, which symbols are erased, and which boundaries define a tradable event. Every rule in that pipeline determines what the classifier can see and what it is forced to ignore.
The dilemma materializes when quantitative researchers treat these transformations as benign standardization rather than active parameterizations of the feature space. A text feature is realized when a preprocessing policy determines the semantic boundary under which that word becomes measurable. Splitting, merging, deleting, lowercasing, masking, or embedding a token changes the geometry of the model input. It alters the sparsity of the design matrix, changes the relationships among features, shifts the timing of event triggers, and reweights the probability of a future market move conditional on the processed text.
Consider the ingestion of a Federal Open Market Committee press release. The raw document is a non-stationary sequence of characters containing policy language, forward guidance, inflation references, balance-sheet terminology, and deliberately controlled ambiguity. If the tokenizer splits on hyphens, the phrase “mortgage-backed” becomes two separate objects rather than one economically coherent instrument descriptor. If a stopword filter removes “not” or “without,” a restrictive sentence may be pushed toward the same representation as an accommodative sentence. If a normalization rule lowercases all symbols, a ticker, acronym, institution, and ordinary noun may collapse into a single token.
The same problem appears in higher-frequency environments. A headline, order-routing message, or execution log may be transformed within milliseconds of arrival. A small parsing decision can determine whether “USD/JPY” remains a currency pair or becomes two unrelated tokens, whether “5.2%” remains a magnitude or becomes an unanchored digit, whether “Order rejected: Code 404” remains distinct from “Order routed: Latency 404ms.” When the preprocessing layer destroys these boundaries, the downstream model may still behave correctly according to its training objective, but it is acting on a distorted version of the event.
Do you want to know more about this? Check that:


Today we argues that text preprocessing in trading systems must be evaluated as part of the signal-generation process rather than as a detachable data-cleaning stage. The relevant question is whether it preserves economically meaningful distinctions under the latency, auditability, and chronological constraints of live trading. A transformation that improves linguistic compactness can still generate negative alpha if it deletes directional modifiers, collapses distinct issuers, introduces future information, or destabilizes the feature basis across time.
Risks and transformation limitations
When preprocessing is decoupled from the objective function of the trading strategy, four structural failure modes emerge. The first risk is semantic inversion. This occurs when a transformation rule reverses the directional polarity of the information. The deletion of negation markers or contrast conjunctions maps risk-reducing statements to risk-escalating feature vectors. In credit trading, the semantic distance between “will default” and “will not default” is the difference between a short and a long position. A generic stopword filter that removes “not” projects both text inputs onto the exact same coordinate in the feature space, forcing the model to calculate an expected return based on a corrupted prior.
The second risk is unstable representation. A fixed concept receives disparate numerical encodings across time intervals or data sources because the preprocessing logic lacks invariance to input formatting. Data vendors frequently update their schema. A news feed might transition from capitalizing standard tickers to formatting them in lowercase within brackets. If the canonicalization logic relies on strict case-matching without entity recognition fallback, the historical feature vector for that asset decays to zero, while a spurious new feature dimension begins accumulating frequency. The model observes this as a sudden regime shift in the underlying asset when it is a mechanical artifact of the data handler.
The third risk is false alignment. Two distinct economic entities or states are collapsed into identical token representations. Stemming protocols force independent market concepts to share an etymological root, inflating feature counts and degrading the precision of the classifier. Truncating “organization” and “organic” to the root “organ” collapses corporate structural news into agricultural commodities data. The classifier inherits a dense, overlapping feature representation that dilutes the predictive power of both original terms.
The fourth risk is operational opacity. Algorithmic systems generate execution and state logs, often communicating via standard protocols such as FIX. Preprocessing frameworks convert these continuous text streams into discrete templates for anomaly detection and latency monitoring. Lossy transformations mask critical dynamic variables, rendering the reconstructed event templates insufficient for post-trade attribution or incident resolution. If a regular expression intended to mask order quantities accidentally masks routing destination tags, the quantitative team loses the ability to diagnose venue-specific slippage.
The key problem for redefining text transformations is a live trading drawdown linked to an information extraction failure. A sentiment classifier parameterized to trade sovereign policy headlines initiated long positions following restrictive policy announcements and short positions following neutral macroeconomic updates. Post-trade analysis isolated the failure to the data transformation layer. A static text processing rule removed contrast terms, reduced specific sovereign entities to generic geographic tokens, and applied morphological stemming that equated distinct central bank actions.
During a critical trading session, a headline reading “Central Bank pauses rate hikes, despite inflation pressures” was ingested. The preprocessing layer stripped “despite” and stemmed “hikes” and “pauses”. The resulting token array fed to the support vector machine lacked the logical dependency structure of the original sentence. The model output a high-confidence positive sentiment score, triggering a large, unhedged long position in the sovereign bond market seconds before a massive sell-off.
The classification algorithm executed correctly given the input vector. The input vector misrepresented the market event because the text transformation policy was optimized for corpus reduction rather than economic fidelity. The post-diagnostics proved that the strategy’s negative alpha was generated within the first twenty milliseconds of the text handling pipeline. This event forces the next question. Must text processing remain rigid, deterministic, and auditable, or should it become contextual, adaptive, and reliant on large language models?

Processing text and features related to text
The prevailing workflow in quantitative text analysis isolates natural language processing from financial modeling. Text is ingested, cleaned, and vectorized using generic linguistic conventions before the quantitative researcher trains a predictive model. This separation is flawed. Let the raw text at time t be xt, and let the preprocessing policy be P. The prediction model f does not observe xt but zt = P(xt). The trading signal is st = f(P(xt)). Therefore, P is a functional operator embedded within the trading strategy. The parameters of P modulate the conditional expectation of the forward return,
We can formalize the optimization problem. The strategy seeks to minimize a risk-adjusted loss function J(θ, P), where θ represents the continuous weights of the classification model and P represents the discrete parameters of the preprocessing policy. Because P consists of non-differentiable string operations, gradient-based optimization fails. Researchers bypass this computational bottleneck by freezing P at generic heuristic defaults and optimizing over θ. This guarantees a suboptimal solution because the feature space itself remains unoptimized for the specific financial task.
Recent advancements in large language models present an alternative to static rules. Neural architectures can resolve linguistic ambiguity conditional on the surrounding text—the regular LLMs everybody knows. They can preserve negation, identify domain-specific entities, and differentiate identical surface strings based on usage. However, replacing deterministic algorithms with generative models introduces latency, variable execution costs, and non-deterministic outputs. High-frequency and mid-frequency statistical arbitrage strategies operate under temporal bounds. Executing a transformer network forward pass introduces latency measured in milliseconds, violating the execution constraints of a strategy engineered for microsecond-level reactions. The quantitative challenge is to engineer a text processing pipeline that extracts the semantic precision of contextual models while maintaining the execution speed and exact reproducibility of static rules.
The first obstacle is the absence of economic loss functions for text operations. Standard linguistic tasks measure success using metrics such as classification accuracy or F1 scores on static text corpora, optimizing for average case performance. The cost of a false positive classification is asymmetric to the cost of a false negative. A transformation rule that improves overall text categorization accuracy by two percent but simultaneously degrades precision on severe, fat-tailed drawdown events produces negative alpha. The preprocessing layer must be calibrated against actual capital deployment metrics, such as maximum drawdown or turnover-adjusted return.
The second obstacle is source heterogeneity. Market text originates from diverse distributions with distinct generative processes. Regulatory filings, such as SEC 10-K and 10-Q documents, are dense, structured, and rely on formal accounting lexicons. Social media feeds are sparse, adversarial, non-standard, and populated with cashtags. Execution logs are machine-generated deterministic strings with dynamic alphanumeric variables. Applying a uniform, global preprocessing operator across these distinct domains guarantees information loss. The pipeline requires domain-conditioned transformation paths.
The third obstacle is look-ahead bias induced by contextual processing. If a large language model relies on weights trained on data generated after time t to process text observed at time t, the resulting feature vector zt contains future information. Pre-trained language representations, whether produced by Word2Vec-style embeddings, BERT-like encoders, GPT-style transformers, or modern embedding models, inherit the temporal context of their training corpus. If a model was pre-trained on a corpus containing 2020 macroeconomic data, validating a 2018 trading strategy using those embeddings constitutes a forward-looking leak. Validating complex text transformations requires chronological segregation of vocabulary sets, embedding spaces, and rule dictionaries. Every artifact must be timestamped and generated only from data available prior to the simulation step.
Lexical canonicalization as a trading signal operator
Lexical canonicalization standardizes heterogeneous text strings into a controlled vocabulary. Market data feeds transmit text with arbitrary capitalization, markup artifacts, and non-standard character encodings. The standard approach applies universal lowercasing and punctuation stripping to reduce the vocabulary dimension and force text convergence.
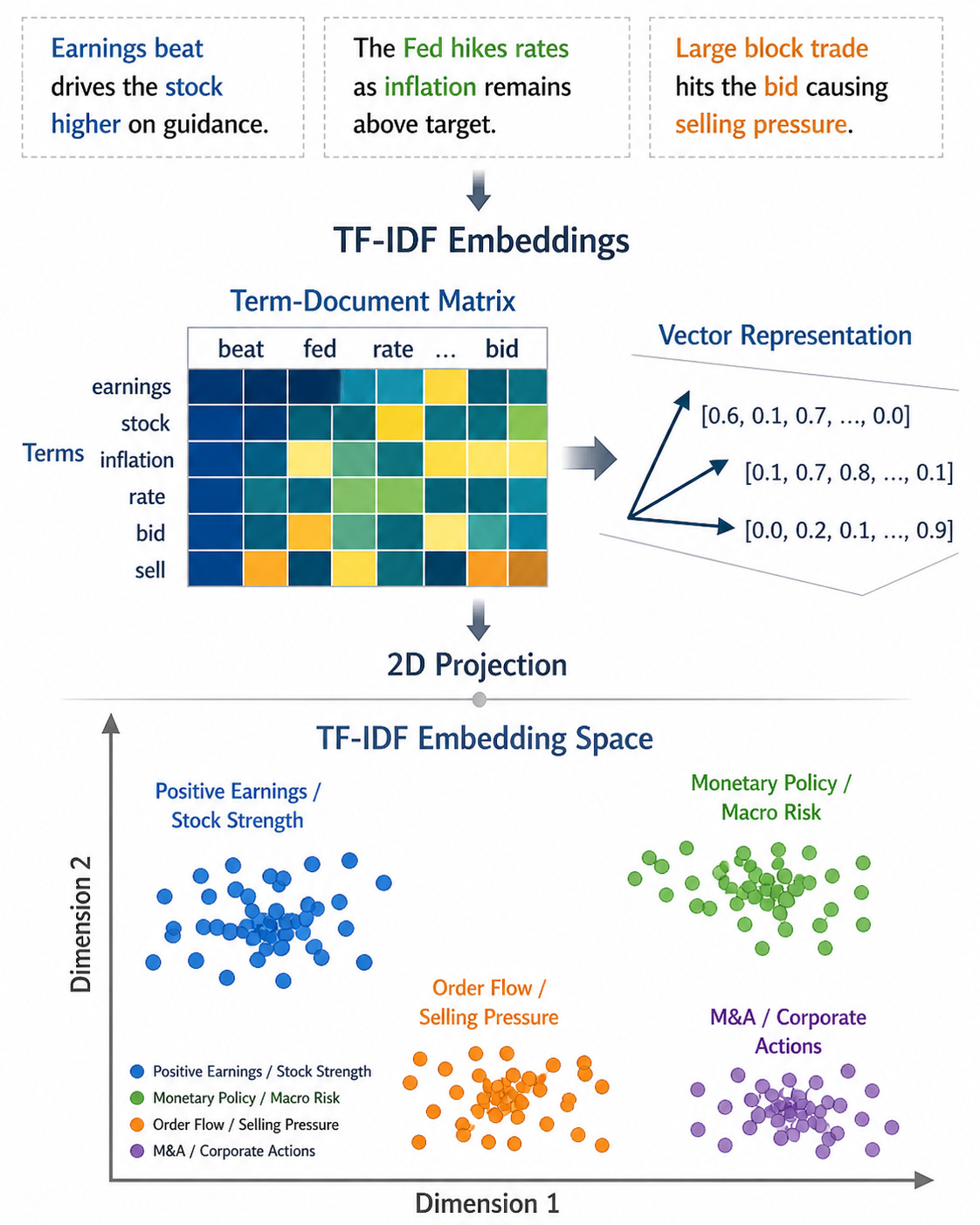
This reduction changes the basis of the feature space. Consider a text sequence mapped to a sparse vector c(x) ∈ N|V|, where |V| is the dimension of the vocabulary and cj(x) represents the occurrence count of token j. A generic canonicalization policy Pa produces vocabulary Va. A domain policy Pb produces vocabulary Vb. The linear combination of features
The transition from a high-dimensional raw text space to a lower-dimensional canonical space is an explicit projection operator.
Canonicalization must be evaluated as an information-theoretic operator. If a token carries distinct economic meaning based on its capitalization—such as the ticker symbol for a listed equity versus a common noun—lowercasing acts as a destructive operator. The string “APPLE” extracted from a financial data vendor carries a probability mass concentrated entirely on a specific technology equity. The string “Apple” might refer to the equity, or it might initiate a sentence. The string “apple” refers to an agricultural commodity. A universal case-folding mapping function collapses these three distinct nodes into a single coordinate. The mutual information between the raw text feature and the target variable is truncated, reducing the upper bound of the classifier’s predictive capability.
To quantify this instability, we define feature turnover when a canonicalization policy is updated or when the underlying data feed shifts formats from Pold to Pnew at time t. Let Vold and Vnew be the active vocabularies observed over a trailing window. Feature turnover is the Jaccard distance between the active feature sets:
High feature turnover indicates that the canonicalization operator is shifting the representation of the market. If τt spikes without a corresponding macroeconomic regime shift or market microstructure event, the canonicalization operator is malfunctioning and injecting mechanical noise into the feature vectors.
import re
from dataclasses import dataclass
from typing import List, Dict, Set
NEGATION = {"not", "no", "never", "without", "neither", "nor"}
UNCERTAINTY = {"may", "might", "could", "expects", "guides", "sees"}
@dataclass(frozen=True)
class ProcessedText:
tokens: List[str]
entities: List[str]
flags: Dict[str, bool]
def normalize_market_text(text: str, known_entities: Set[str]) -> ProcessedText:
"""
Standardizes text while preserving case-sensitive market entities and
extracting logical flags before irreversible lowercasing.
"""
# Remove basic HTML markup
text = re.sub(r"<[^>]+>", " ", text)
# Normalize whitespace
text = re.sub(r"\s+", " ", text).strip()
# Extract entities preserving case. This prevents "APPLE" from becoming "apple"
entities = [e for e in known_entities if e in text]
# Tokenize broadly, capturing percentages and punctuation
raw_tokens = re.findall(r"[A-Za-z][A-Za-z.'\-]*|\$?\d+(?:\.\d+)?%?|[!?]", text)
tokens = []
for tok in raw_tokens:
if tok in entities:
# Preserve exact case for known entities
tokens.append(tok)
elif tok.lower() in NEGATION or tok.lower() in UNCERTAINTY:
# Standardize logical operators
tokens.append(tok.lower())
else:
# Fallback canonicalization
tokens.append(tok.lower())
# Extract boolean flags representing the logical geometry of the sequence
flags = {
"has_negation": any(t in NEGATION for t in tokens),
"has_uncertainty": any(t in UNCERTAINTY for t in tokens),
"has_percent": any(t.endswith("%") for t in tokens),
}
return ProcessedText(tokens=tokens, entities=entities, flags=flags)The next plot visualizes the baseline accuracy variances across disparate datasets under different canonicalization regimes, demonstrating that baseline controls are necessary. A robust canonicalization policy avoids global destructiveness. It extracts protected entities using deterministic gazetteers and named entity recognition modules before applying generic, dimension-reducing transformations to the residual text.
Token boundary specification and market microstructure semantics
Token boundary specification determines the minimum atomic unit of information available to the prediction model. Generic tokenizers partition text using whitespace and standard punctuation delimiters. Financial text consistently violates the core assumptions of generic tokenization, relying on special characters to denote specialized meaning.
Consider market identifiers and quantitative formats. Ticker symbols contain periods to denote share classes (BRK.B). Currency pairs rely on forward slashes (USD/JPY). ISINs and CUSIPs contain structured alphanumeric sequences without spacing. Magnitudes are similarly complex. Interest rates combine digits, decimal points, and percentage signs without whitespace, while financial statements combine currency symbols, numerical digits, and alphabetical magnitude modifiers (e.g., $1.5B). A generic tokenizer fractures these sequences blindly based on static delimiter rules. The string “USD/JPY” becomes
The explicit, hard-coded relationship between the base currency and the quote currency is severed.
When token boundaries are misspecified, the classifier must relearn the fractured relationship through computationally expensive sequence modeling or n-gram concatenation. This increases the data requirement to reach statistical significance and reduces the overall statistical power of the model. Token boundary specification in algorithmic trading must construct typed semantic spans.
Let x be the raw text string. A financial tokenizer first applies an ordered set of regular expressions R to identify protected spans E(x). Conflicts and overlaps are resolved using explicit priority queues, ensuring that a longer, more specific match supersedes a generic match. The tokenizer then partitions the complement sequence x\E(x) using standard whitespace rules. The output is an ordered sequence of discrete tokens interleaved with immutable typed entities.
The probability distribution of market events is conditional on these typed spans. An earnings surprise is a function of a specific reporting entity combined with a numerical magnitude measured relative to a predefined consensus estimate. If the tokenizer fractures the magnitude, the model receives unanchored digits. The feature vector contains noise rather than signal. Let’s implement it.
def protected_tokenize(text: str) -> List[str]:
"""
Applies regex to extract specific market boundaries (money, percentages, ratings)
before standard tokenization shatters them into unanchored digits.
"""
patterns = {
"MONEY": r"\$\d+(?:\.\d+)?(?:\s?-\s?\$?\d+(?:\.\d+)?)?",
"PCT": r"[-+]?\d+(?:\.\d+)?%",
"RATING": r"\b(?:AAA|AA|A|BBB|BB|B|CCC|CC|C|D)[+-]?\b",
"FX": r"\b[A-Z]{3}/[A-Z]{3}\b",
"FILING": r"\b(?:10-K|10-Q|8-K|S-1)\b"}
spans = []
for label, pat in patterns.items():
for m in re.finditer(pat, text):
spans.append((m.start(), m.end(), label, m.group()))
# Sort by start index, resolve overlaps by taking the longest match
spans = sorted(spans, key=lambda s: (s[0], -(s[1]-s[0])))
tokens = []
i = 0
for start, end, label, raw in spans:
if start < i:
continue # Skip overlapping spans
# Tokenize text BEFORE the protected span
tokens.extend(re.findall(r"[A-Za-z][A-Za-z'\-]*|\d+|[!?]", text[i:start]))
# Append the protected span as a single, typed token
tokens.append(f"<{label}:{raw}>")
i = end
# Tokenize any remaining text after the last span
tokens.extend(re.findall(r"[A-Za-z][A-Za-z'\-]*|\d+|[!?]", text[i:]))
return tokensThe impact of tokenization extends into the temporal precision of market microstructure events. Execution logs and limit order book updates record exact latencies, side, and sequence numbers. A message reading “ADD order 12345 100@150.50” must not be parsed into arbitrary digits. Misspecifying the boundary of a timestamp, an order identifier, or a price-quantity tuple corrupts the sequence alignment. If the text pipeline fails to generate <QTY>@<PRICE>, the parser cannot reconstruct the state of the limit order book accurately, destroying the integrity of the downstream order flow imbalance calculations.
