


Table of contents:
Introduction.
Option 1: Broker data.
Option 2: Free data.
Option 4: Data lakes.
Building your own mini data lake environment!
Step 1 - Finding data sources.
Step 2 - Batch data processing.
Step 3 - Data ingestion and cleaning.
Step 4 - Data storage.
Before you begin, remember that you have an index with the newsletter content organized by clicking on “Read the newsletter index” in this image.

Introduction
Ah, data! The lifeblood of any quant, the secret sauce of statistical alchemy, and the fuel that powers our mathematical engines.
Without it, we’re simply quants twiddling our thumbs, staring at blank screens, and scribbling equations on napkins that may or may not lead to groundbreaking insights. But where does this elusive, magical data come from? And more importantly, how do we transform it from a jumbled mess into a refined, actionable trading strategy that doesn’t, well, lose all our money?
Before we set out on our grand quest, we must first understand the different avenues available for acquiring our precious data. Picture these as the Four Horsemen of the Data Apocalypse—each with its own distinct style, perks, and quirks.
Option 1 - Broker data–aka the freebie with strings attached:
Imagine your broker as that well-meaning friend who offers you a ride when you’re stranded but then casually reminds you to pay for the gas afterward. Broker data is akin to this ride: you get access to historical market data and real-time bid-ask, which is essential for basic analysis and testing strategies.
However, there’s a catch. Much like a pizza with only half the toppings, the data can be limited, leaving you hungry for more comprehensive insights. For example, if your broker only provides five years of historical data, you might miss out on those rare market events that occur only once a decade. Aside from the horrors and nightmares we have to deal with, as we saw here [Errors]
It’s also true that sometimes, if they’re feeling generous, you might even catch a glimpse of the DOM–This is from MT5, probably your broker is receiving this data from contract providers, type CFDs (drama).
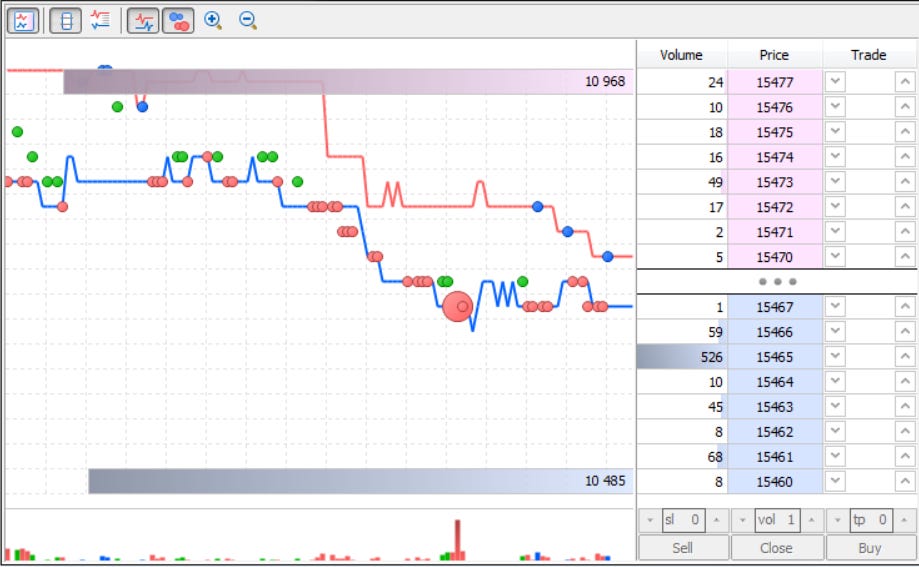
Option 2 - Free data–aka the wild west of the Internet:
Next, we have free data—the digital treasure hunt of the quant world. Free data is abundant and comes in many forms: historical price data, economic indicators, and even regulatory filings.
However, it’s a bit like rummaging through a garage sale. Sometimes you find hidden gems, and other times you end up with a box of mismatched, outdated, or poorly formatted information. One must tread carefully in this Wild West of data, where missing values, delayed updates, or bizarre formats might leave you scratching your head—Martian time stamps, anyone?
Yes, indeed, I am referring to the infamous Yahoo API:
import yfinance as yf
# Download Tesla stock data from January 1, 2020 to January 1, 2023
data = yf.download("TSLA", start="2020-01-01", end="2025-01-01")
print(data.head())This snippet is simple, yet effective—unless the data arrives with missing timestamps, delayed or other quirky issues, in which case your cleaning process might soon resemble a detective story with more red herrings than clues.
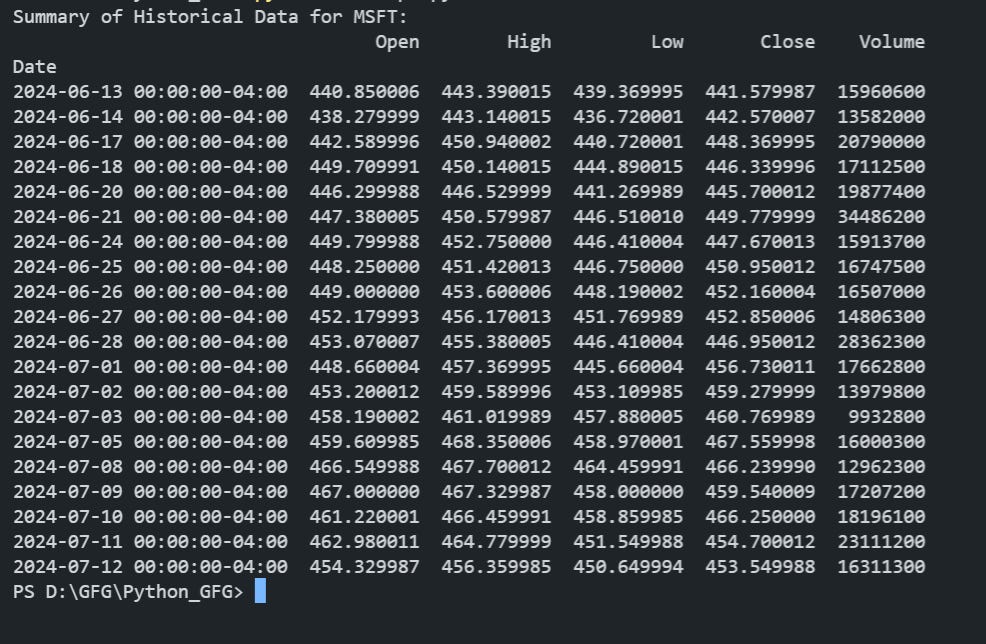
Option 3 - Paid data–aka the luxury option for retails:
Now, imagine stepping into a high-end boutique, where every product is meticulously curated, and quality is guaranteed—but at a premium price. Paid data is like buying a first-class ticket to data paradise. It offers high-quality, comprehensive datasets that are updated regularly and maintained with rigorous attention to detail. Whether it’s tick-level market data, in-depth fundamental metrics, or alternative datasets, paid data is your golden ticket.
However, be warned: luxury comes at a price and I understand that not everyone can afford it as a hobby. In fact, you might find that the cost of your data is as steep as the learning curve on quantum mechanics–and trust me, that curve is steep!
With paid data, you’re likely to have more accurate predictors, but even then, the model must be validated carefully. After all, as we say in the quant world: garbage in, garbage out—even if the garbage was imported with extra care.
In this case you have this is a sample of Databento, higher quality and better integration.
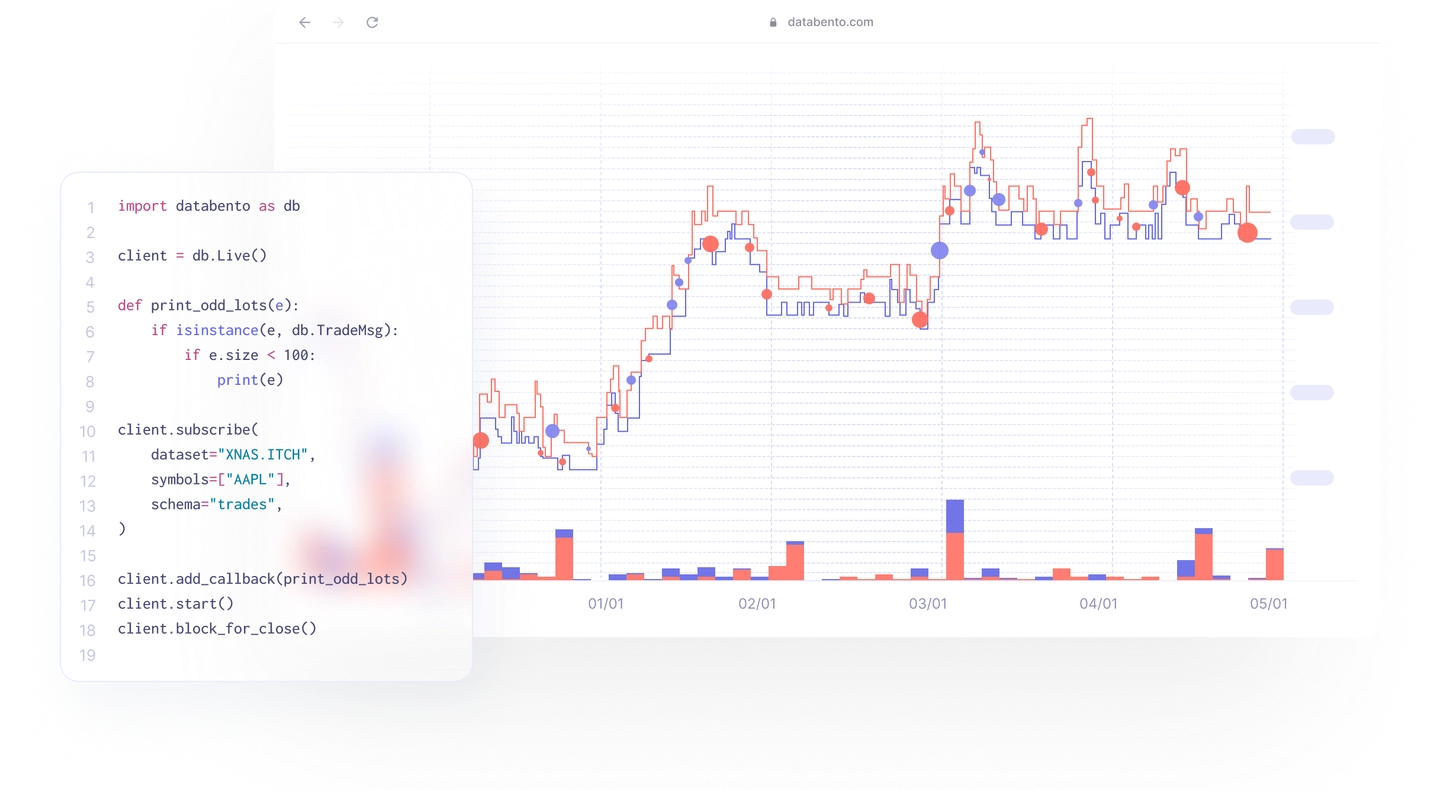
Option 4 - Data lakes–aka the corporate dream:
Finally, we reach the realm of data lakes—a vast, deep repository where structured, semi-structured, and unstructured data flow together like a mighty river. If you’re part of a large organization, you might have access to a data lake that would make even the most experienced sailor jealous. But for the retail trader, a data lake can feel as unreachable as a private island in the middle of the Atlantic.
In a data lake, you can mix financial statements with multimedia, social media feeds with market data, and even ancient scrolls of economic history–okay, maybe not ancient scrolls, but you get the idea. It’s a corporate dream come true, as long as you have the resources and know-how to swim in its vast depths.

Now that we’ve surveyed the four primary sources of data, let’s move on to the next phase: How to build your own data lake!? It’s time to roll up our sleeves and get our hands dirty with some good old-fashioned data processing!
Building your own mini data lake environment!
Having chosen your data sources, the next logical step is to build an environment where your data can thrive. Whether it’s a sprawling data lake or a modest data pond, the process involves a few key steps: finding data sources, processing your data in batches, ingesting and cleaning it, and finally, storing it in a coherent and efficient manner.
Step 1 - Finding data sources:
The first step in our data episode is akin to assembling a superhero team. You need a diverse set of data sources—financial statements, market valuations, price quotes, news articles, SEC filings, and even social media feeds—to create a robust and versatile dataset. Think of it as building your own Frankenstein’s monster, but instead of cobbling together body parts, you’re stitching together datasets from various origins.
Wait, wait, here comes a good one: Why did the data scientist break up with their dataset? Because it just wasn’t giving them the “connection” they needed! ahaha! Okay, sorry about that. Here some interesting sources:
iex —free market data.
one tick—historical tick data.
iqfeed—real time data feed.
quantquote—tick and live data.
algoseek—historical intraday.
EOD data—historical data.
intrinio—financial data.
arctic—igh performance datastore from Man AHL for time series and tick data.
SEC EDGAR API—query company filings on SEC EDGAR.
The question here is: If I want to take all the sources at once to combine them, how do I do it?

Step 2 - Batch data processing: