

[WITH CODE] Features: Incremental feature selection
Introducing the fully automated incremental OMP methodology

Table of contents:
Introduction.
Classical Orthogonal Matching Pursuit.
Fully automated incremental OMP.
Incremental QR update.
Robust noise estimation via MAD.
Z‑Score normalization for non‑stationarity.
FA-OMP incremental algorithm implementation.
Before you begin, remember that you have an index with the newsletter content organized by clicking on “Read the newsletter index” in this image.

Introduction
Who doesn't use a feature selection method? Questions here, feature this, and blah blah blah, questions there, and feature this, and lalala. Well, let's look at a rather interesting technique. The original method has quite a few flaws, but many of them have been eliminated with today’s implementation. I’m refering to the Orthogonal Matching Pursuit method.
This type of method have long been used in compressed sensing and signal processing, but classical OMP is known to suffer from pitfalls like greediness, sensitivity to noise, and high computational costs.
But first things first, let's see an introduction of the class method and then the improved version.

Classical Orthogonal Matching Pursuit
In order to understand it we have to take into account the sparse representations and the ℓ₀-norm.
So given an observation vector
and a dictionary
we assume that y can be expressed as
where w∈RN is a sparse coefficient vector—i.e., it has only a few nonzero entries—and e represents noise. The sparsity of w is often measured using the so-called ℓ₀-norm:
Finding the sparsest solution is NP‑hard, which motivates the use of greedy algorithms.
So what does this technique consist of? It is a iterative algorithm that selects one dictionary atom at a time. At each iteration t, OMP computes the residual
where Λt-1 is the set of indices selected so far. The next atom is chosen as
After adding the new atom, the algorithm updates the coefficient vector wΛt by solving the least-squares problem:
You can check it by using this snippet:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import OrthogonalMatchingPursuit
# Set a random seed for reproducibility
rng = np.random.RandomState(42)
# 1. Generate synthetic data
n_samples = 40 # Number of samples
n_features = 100 # Number of features (dictionary atoms)
n_nonzero_coefs = 5 # True number of nonzero coefficients
# Design matrix (dictionary)
X = rng.randn(n_samples, n_features)
# True (sparse) coefficients
w_true = np.zeros(n_features)
# Randomly pick positions for the nonzero coefficients
idx = rng.choice(np.arange(n_features), n_nonzero_coefs, replace=False)
# Assign random values to these positions
w_true[idx] = rng.randn(n_nonzero_coefs)
# Generate target values
y = X @ w_true
# 2. Fit Orthogonal Matching Pursuit
omp = OrthogonalMatchingPursuit(n_nonzero_coefs=n_nonzero_coefs)
omp.fit(X, y)
# Recovered coefficients
w_estimated = omp.coef_If we plot this, we get:
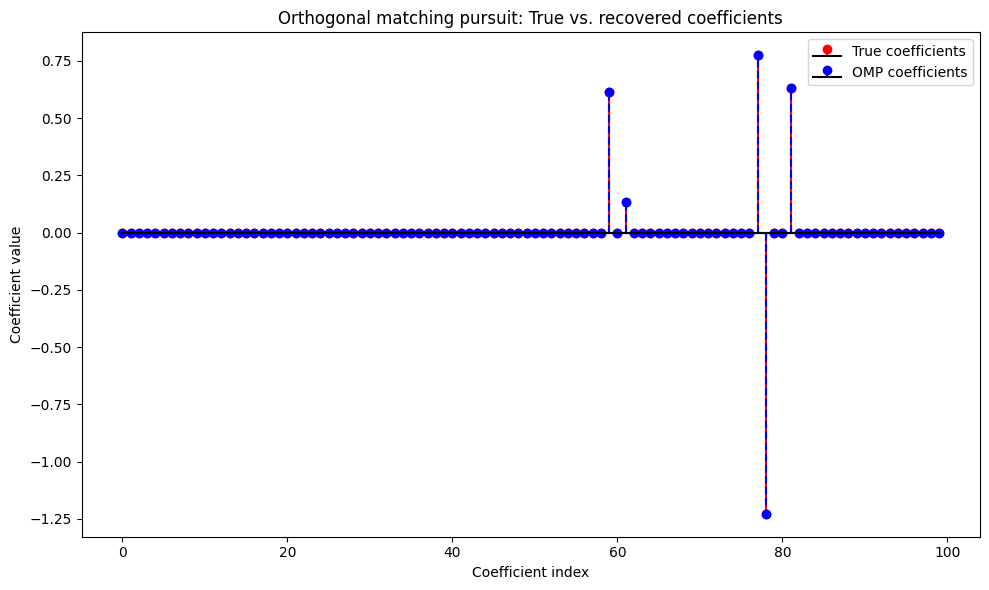
The plot shows both the true coefficients and the ones recovered by OMP.
Despite its simplicity, classical OMP suffers from:
Early incorrect selections are irreversible, potentially leading to suboptimal global performance.
Noise can distort correlation measurements, resulting in the selection of irrelevant atoms.
Repeatedly solving full least-squares problems is expensive.
Manual tuning is needed for thresholds and stopping criteria.
At the beginning my goal was to address these issues through automation, incremental updates and robust noise estimation. But as I solved one problem, another appeared. Until I was finally able to establish a method.

Fully automated incremental OMP
There are several points that have had to be changed a priori if the goal is to achieve an incremental release. Let's start with the first one.
Incremental QR update
Suppose that after k iterations we have the selected sub-dictionary XΛt with its QR decomposition:
where Q∈RM×k is an orthonormal matrix and R∈Rk×k is upper-triangular. When a new atom a is added, we wish to efficiently compute the QR decomposition of the augmented matrix
We first project a onto Q:
and compute the residual
Its norm is
If rnorm is significant, we form
and update the basis:
and the upper-triangular factor becomes:
This update is encapsulated in our helper function incremental_qr_update. As we will see in the final version.
Let’s put this into code:
import numpy as np
import matplotlib.pyplot as plt
def incremental_qr_update(Q, R, a):
"""
Incrementally update the QR decomposition when adding a new column a.
Given Q (M x k) and R (k x k) such that A = Q @ R, where A consists of
previously selected atoms, compute the QR of [A, a].
"""
p = Q.T @ a # Projection of a onto Q, shape (k,)
r_vec = a - Q @ p # Residual component of a
r_norm = np.linalg.norm(r_vec)
if r_norm < 1e-12:
# Nearly in the span of Q; avoid division by zero.
r_norm = 1e-12
new_col = np.zeros_like(a)
else:
new_col = r_vec / r_norm
Q_new = np.column_stack([Q, new_col])
R_new_top = np.column_stack([R, p.reshape(-1, 1)])
R_new_bottom = np.zeros((1, R.shape[1] + 1))
R_new_bottom[0, -1] = r_norm
R_new = np.vstack([R_new_top, R_new_bottom])
return Q_new, R_newRobust noise estimation via MAD
Classical OMP requires an estimate of the noise standard deviation σ. In non‑stationary environments like trading, a fixed noise estimate can be misleading. We therefore adopt a robust noise estimation technique using the median absolute deviation of the residual:
and approximate
This robust estimate updates as the algorithm proceeds and is used to adapt the correlation threshold dynamically. 0.6745 is constant used for normal distributions—remember that we will normalize our data with the next step.
That’s easy!
def robust_noise_estimation(residual):
"""
Estimate noise standard deviation robustly using the Median Absolute Deviation (MAD).
"""
med = np.median(residual)
mad = np.median(np.abs(residual - med))
sigma = mad / 0.6745 # Constant for normal distribution
return sigmaZ‑Score normalization for non‑stationarity
To address non‑stationarity, we preprocess the dictionary X by converting each column into its z‑score:
where μj and σj are the mean and standard deviation of the j‑th column. This transformation ensures that features are standardized, thus making the correlation comparisons more reliable over time.
FA-OMP incremental algorithm implementation